
| Moderador del foro: ZorG |
| Foro uCoz Ayuda a los webmasters Soluciones personalizadas Fundamentos de HTML |
| Fundamentos de HTML |
En este tema voy a tratar de explicar lo más esencial y necesario que debe saber cualquier novato empezando a ir creando su web. Pero de todo modo yo invito a todos que dejen sus comentarios acerca del tema, su experiencia, puntos de vista etc.
Finalizando la parte principal, todo esto ha de verse de manera siguiente:
Code <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>Sitio web : situación en la web : título del tema</title> <meta name="author" content="Aquí está tu nombre"> </head> <body> <!-- Área de contenido principal--> </body> </html>
Ahora quiero contar un poco sobre el texto. Utilización correcta de los títulos.
Code <h1>Ucoz Web-Services</h1> <h2>Una nueva mirada a la creación de las webs</h2> Adición de los párrafos. Control de los párrafos se realiza con ayuda del elemento de párrafo, </p>.
Code <p>Sistema de gestión del sitio web El único sistema de gestión del sitio web, que permite crear tanto una web estática como la dinámica.</p> <p>Una nueva generación de servicios Web. Al fin y al cabo la creación de una web es un proceso fácil y fascinante...</p> Tag de brecha de la línea
Code <p>Por una mirada – un mundo,<br /> Por una sonrisa – un cielo.<br /> Por un beso – yo no sé,<br /> Que te diera por un beso.</p> Lista ordenada. Para crear una lista ordenada se requieren dos elementos:
Code <ol> <li>Regístrate en el sistema UCOZ</> <li>Estudia el sistema con toda la escrupulosisdad</li> <li>Crea tu sitio web</li> </ol> Lista desordenada.
Code Lista de servicios en el sistema UCOZ</p> <ul> <li>Editor del sitio</li> <li>Libro de visitas</li> <li>Foro</li> <li>Catálogo de artículos</li> <li>Blog</li> <li>Álbumes de fotos</li> <li>Noticias del sitio</li> <li>Catálogo de archivos</li> <li>FAQ</li> <li>Encuestas</li> <li>Formularios de correo</li> </ul>
Elemento TABLE La creación de las tablas se empieza desde el elemento table. Este element se considera no vacío, por eso se escribe con la aplicación de los tags de apertura y cierre:
Code <table></table> Ancho de la tabla. El ancho de una tabla se configura de 2 métodos: en pixels y en %.
Code <table width="250"> </table> Mirar aquí para ver el ejemplo El valor expuesto en % se considera dinámico, pues la tabla ocupará el espacio expuesto en por ciento respecto el espacio libre de la pantalla del navegador.
Code <table width="90%"> </table> Mirar aquí para ver el ejemplo Límites de la tabla e intervalos. Lenguaje HTML permite activar la exposición (visualización) de los límites de las tablas:
Code <table width="250" border="1"> Por resultas del cumplimiento de esta línea alrededor de la tabla y todas sus líneas y celdas se expondrá un límite con el ancho de 1 pixel. Para añadir un intervalo entre las celdas se utiliza el atributo cellspacing.
Code <table width="90%" border="1" cellspacing="5" cellpadding="5"> Mirar aquí para ver el ejemplo Adición de las líneas de la tabla. Se añade una línea en la tabla con ayuda del elemento tr:
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> Datos </tr> </table> Puede contener la tabla cualquier número de líneas que sea necesario. Adición de las celdas de la tabla. Las celdas forman las columnas verticales con ayuda de los tags <td></td>.
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> <td>Datos</td> <td>Datos</td> <td>Datos</td> </tr> </table> Mirar aquí para ver el ejemplo Adición de los títulos de las tablas. El título de la tabla quiere decir el título de una columna o una línea de la tabla.
Code <th> </th> Para que los títulos describan las columnas que están bajo de éstos, sitúa todos los títulos en una línea, luego añade las columnas que estarán bajo los títulos en las líneas posteriores.
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> <th>Ubicación</th> <th>Tiempo (atmosférico)</th> <th>Huso horario</th> </tr> <tr> <td>España, Маdrid</td> <td>Caliente</td> <td>Día es largo</td> </tr> </table> Mirar aquí para ver el ejemplo Los títulos también pueden utilizarse para describir los títulos de las líneas.
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> <th>Ubicación</th> <td>España, Маdrid</td> </tr> <tr> <th>Tiempo (atmosférico)</th> <td>Caliente</td> </tr> <tr> <th>Huso horario</th> <td>Día es largo</td> </tr> </table> Mirar aquí para ver el ejemplo Unificación de las líneas. En el proceso de crear tablas puede surgir la necesidad de extender una columna a costa de varias líneas, pa’ esto existe un atributo rowspan, cuyo valor determina el número de líneas.
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> <th rowspan="2">Título (unificadas 2 líneas)</th> <td>Datos</td> <td>Datos</td> </tr> <tr> <td>Datos</td> <td>Datos</td> </tr> <tr> <th>Título (sin unificación)</th> <td>Datos</td> <td>Datos</td> </tr> </table> Mirar aquí para ver el ejemplo También es posible unir las líneas dentro de las celdas.
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> <th rowspan="2">Título (unificadas 2 líneas)</th> <td rowspan="3">Datos (unificadas 3 líneas)</td> <td>Datos</td> </tr> <tr> <td>Datos</td> </tr> <tr> <th>Título (sin unificación)</th> <td>Datos</td> </tr> </table> Mirar aquí para ver el ejemplo Unificación de las columnas. Igualmente como la unificación de las líneas, se puede unir las columnas. Para esto aplicamos el atributo colspan.
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> <th colspan="2">Título (unificadas 2 líneas)</th> <th>Título (sin unificación)</th> </tr> <tr> <td>Datos</td> <td>Datos</td> <td>Datos</td> </tr> <tr> <td>Datos</td> <td>Datos</td> <td>Datos</td> </tr> </table> Mirar aquí para ver el ejemplo De la misma manera se puede unir las celdas de la tabla.
Code <table width="90%" border="1" cellspacing="10" cellpadding="10"> <tr> <th colspan="2">Título (unificadas 2 columnas)</th> <th>Título (sin unificación)</th> </tr> <tr> <td>Datos</td> <td>Datos</td> <td>Datos</td> </tr> <tr> <td colspan="3">Título (unificadas 3 columnas)</td> </tr> </table> Mirar aquí para ver el ejemplo ADVERTENCIA: tengan cuidado y estén atentos cuando utilizan los atributos colspan y rowspan, pues éstos les pueden embrollar. Recuerden que la unificación de las líneas significa unificación vertical, y la unificación de las columnas significa unificación horizontal. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
ELEMENTOS EN HTML Elemento <IMG> Se utiliza para poner una imagen gráfica en el cuerpo del documento. Imagen gráfica quiere decir pequeños pictogramas, dibujos, objetos gráficos y mapas que ocupan mayor parte de la pantalla del navegador. Además, el <IMG> mantiene distintos atributos. Este atributo indica al archivo del gráfico dando su URL. En algunas ocasiones, cuando el navegador no puede cargar un archivo con la imagen, con el fin de economizar el tiempo y moneda en la pantalla desactiva la subida de las imágenes, y en la pantalla se expone un texto alternativo, por ejemplo Aquí se expone el logotipo de la empresa . Ejemplo: <img src="http://ucoz.com/img/image.jpg" alt="Aquí se expone el logotipo de uCoz"> Este atributo configura el ancho del área en pixels que se da en la pantalla para situar una imagen. Ejemplo: <img src="http://ucoz.com/img/image.jpg" alt="Aquí se expone el logotipo de uCoz" width="100"> Este atributo configura el alto del área en pixels que se da en la pantalla para situar una imagen. Ejemplo: <img src="http://ucoz.com/img/image.jpg" alt="Aquí se expone el logotipo de uCoz" width="100" height="50">
Introducción a los elementos y etiquetas de HTML ¿Qué es el HTML? Un archivo HTML es un archivo de texto normal, salvo por el hecho de que contiene etiquetas de formato o marcaje. En HTML, usamos "etiquetas" (tags) para crear la estructura de una página web. Estas etiquetas indican al navegador cómo mostrar el texto y las imágenes en el documento. Los archivos HTML deben tener la extensión .htm o .html para que se interpreten correctamente por un navegador como Internet Explorer. Al ser un archivo de texto, se puede crear un archivo HTML utilizando cualquier editor de texto corriente, como el Bloc de notas, WordPad o MSWord, etc. Etiquetas lógicas en HTML (logical inline tags) • <strong>: marca un texto en negrita, denota importancia. Aunque estas etiquetas lógicas tienen una forma predeterminada de mostrarse en los navegadores (como Internet Explorer o Firefox), se entiende que el CSS se debería utilizar para darles la apariencia deseada y crear así el diseño de una página web. Etiquetas de bloque vs etiquetas de línea Elementos de bloque en HTML (block elements) Elementos de línea en HTML (inline elements) El texto en negrita está contenido dentro de un elemento de línea o inline tag, en este caso <strong>. Aquí el código: Así, un ejemplo de una etiqueta de bloque es un <div> (caja) ó un <p> (párrafo) y un ejemplo de una etiqueta de línea es la <b> (negrita). Para entender este concepto lo más sencillo es probar lo que sucede en un texto cuando se introducen ambos, haz la prueba. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Conceptos básicos de HTML HTML se basa en principalmente en etiquetas, que son como instrucciones para dar formato a las diferentes partes de una página web. Para toda persona interesada en crear páginas web es importante conocer al menos nociones básicas de este lenguaje, de esta forma podemos comprender como están hechas las páginas web, desarrollar sitios con más flexibilidad y mejor construidos. Etiquetas básicas Ejemplo de página básica <title>Título de la página</title> </head> <body> <h1>Encabezado de la página</h2> <h3>Encabezado de menor tamaño</h3> Este es el texto de un párrafo.</p> Este es el texto de otro párrafo. Dentro de este párrafo, pueden ir palabras en negrita, en cursiva o lo que quieras.</p> También podemos poner listas como la siguiente:</p> </body> </html> Y para que lo entiendas mejor, una página básica con su correspondiente código HTML: Introducción 1. El HEAD o cabecera, donde está la información sobre la página web, como el título, una breve descripción y algunas palabras clave. También puede contener información de estilos (CSS) y librerías JavaScript. Las siguientes etiquetas HTML se utilizan para construir la estructura básica de una web: Estructura básica en HTML <html> No existen directivas definitivas para un “buen” HTML. Sin embargo existen normas sobre el aspecto que debe tener un documento HTML. En todo caso es recomendable orientarse lo más posible a las normas del lenguaje según el Consorcio(W3C). Entretanto, el Consorcio(W3C) ha reconocido que su tarea no sólo es la elaboración de prescripciones técnicas, sino también la mediación a los usuarios “comunes” que no poseen un estudio informático acabado. En caso de que se ocupe de la creación de páginas web de una manera intensiva y duradera, le recomendamos visitar regularmente las páginas del Consorcio (W3C) y ver las novedades, tendencias y directivas. El Consorcio (W3C) ofrece además para autores de HTML un servicio, para examinar la exactitud sintáctica de archivos: el llamado validador. De esta forma puede examinar sus páginas en busca de errores para corregirlos. No codificar para un determinado navegador Nadie le puede prohibir que escriba sus archivos HTML para un navegador determinado, por ejemplo Netscape (como muchas personas lo hacen). En tal caso es recomendable informar en la página de entrada que las páginas han sido desarrolladas para un determinado navegador. Nosotros aconsejamos buscar un compromiso para que las páginas puedan ser visualizadas por todos los navegadores. No codificar para determinadas resoluciones de pantalla Utilice indicaciones de altura y anchura en porcentajes, para las tablas y marcos. Indicaciones absolutas de píxeles tienen un sentido allí, en donde la primera columna de una tabla invisible se debe encontrar sobre una imagen de fondo coloreada partida en dos. Por lo demás debe abandonar la idea de que por ejemplo una imagen o un párrafo deben comenzar exactamente 10,8 cm del borde izquierdo de cada navegador. Si la página se ve bien en su navegador, eso no significa que en los navegadores de los usuarios también se vea bien, en algunos casos es de esperar que la visualización sea realmente mala. No utilizar los elementos HTML para otros fines Pero aun mucho peor es la utilización incorrecta de cabeceras. Las cabeceras no existen para hacer que los textos sean más grande y estén en negrita, sino para marcar las relaciones jerárquicas lógicas entre los diferente párrafos. Si desea hacer formatos sobresalientes, utilice para ello las hojas de estilo en cascada. Utilizar textos de enlaces honestos y explícitos Enlaces pueden ser puestos en cualquier lugar del texto. Pero si lee un texto, en el cual cada segunda palabra es un enlace, entonces se podrá dar cuenta que eso molesta definitivamente la lectura. El motivo de esto, es que uno siempre pone atención a los enlaces, y eso nos molesta al leer. Por esta razón es de suma importancia que los enlaces en los textos no se conviertan en adivinanzas, sino al contrario, al leerlos, el usuario debe darse una idea de lo que se esconde detrás de ellos. Utilice siempre un enlace dentro del texto, siempre y cuando el texto del enlace sea razonable. Formule oraciones, en donde aparezca el texto del enlace, de tal manera que se pueda comprender de lo que se trata. No escriba por ejemplo: sino: Utilizar imágenes correctamente Por tal razón le aconsejamos que utilice imágenes web pequeñas bien posicionadas. Muchas veces basta tener imágenes con 16 colores en lugar de 256 o hasta de 16,7 millones. Esto hace que las imágenes sean más pequeñas y carguen más rápido las páginas web. Por otro lado no hay que prescindir de gráficos. Leer sólo texto en la pantalla cansa mucho más que por ejemplo en un libro. Por tal razón es recomendable estructurar los textos largos. La utilización de imágenes también forma parte de ello. Las imágenes pequeñas en forma de iconos son ideales. Ellos se cargan bien rápido y se pueden utilizar varias veces en un mismo archivo HTML.
(Tomado de http://lawebera.es )
Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Un verdadero curso sobre HTML.
En mi opinion todo lo que se dedica a estos tipos de trabajo, no importa si es SEO, diseño Web o otras cosas que tiene que ver con la Web en general, deberia tener concimientos sobre HTML. |
CÓMO CREAR ENLACES HIPERTEXTO Para ser capaces de crear una página Web bastante completa tenemos que aprender a crear enlaces hipertexto. Con ellos se pueden activar frases o palabras de la página para que al pulsar sobre ellas se salte a cualquier otra página de Internet que decidamos. Estos enlaces hipertexto (en inglés links) no son más que unas zonas (habitualmente palabras o frases) especiales de nuestro texto que ofrecen la posibilidad de pulsar sobre ellas para ir a otras páginas. El concepto del hipertexto no es nuevo, la mayoría de los lectores lo habrán usado ya en la ayuda de Windows™ o en otros muchos sistemas, lo realmente novedoso que ofrecen estos enlaces en el WWW es la posibilidad de pulsar y navegar hasta páginas que se encuentren en el otro extremo de la tierra. El navegante puede moverse de España a Japón con una única pulsación sobre el texto adecuado. En seguida se verá lo sencillo que es incluir esta impresionante tecnología en una página web. Los enlaces pueden clasificarse en dos tipos, los internos o locales y los externos: 1. Los enlaces internos son aquellos que enlazan las páginas que componen un mismo sitio web (web site). Todas estas páginas estarán (generalmente) en el mismo servidor WWW, y por tanto estarán también en el mismo ordenador. Por esta razón sólo será necesario indicar en nuestro código el nombre del archivo donde está la página que queremos enlazar y el directorio en el que se encuentra. Un ejemplo dirección de un enlace interno es:
Quote /hobbies/index.html 2. Los enlaces externos permiten saltar desde una página hasta otra puede estar en cualquier otro lugar del mundo en otro servidor web. Al crear estos enlaces es necesario especificar la dirección completa de Internet (la URL) de la página que queremos enlazar. Por ejemplo:
Quote http://www.otroservidor.com/hobbies/index.html Por último, cabe resaltar que aunque la mayoría de las veces los links se usan para enlazar una página con otras también pueden usarse con imágenes, sonido, vídeo y prácticamente cualquier tipo de fichero. La etiqueta <a>… </a>
Quote <a href="dirección_URL">Hipertexto</a> Los navegadores gráficos como Netscape Navigator y Microsoft Internet Explorer resaltan este texto mostrándolo de un color diferente y subrayándolo, además el cursor cambiará al situarlo sobre el texto. Los navegadores que funcionan en modo texto como Lynx resaltan los enlaces hipertexto cambiando el color del texto y de su fondo. Veamos un ejemplo sencillo del uso de enlaces. Se ha creado un sitio web personal con 2 páginas. La página principal se encuentra en el archivo index.html y se quiere que en ella haya un enlace a otra página donde se han escrito sobre los hobbies del creador del sitio web y que se encuentra en el archivo hobbies.html. El enlace podría ser algo así:
Quote Puedes conocer mis <a href="hobbies.html">hobbies</a> Si no funciona un link conviene comprobar la sintaxis del código HTML. Un error común es no cerrar las comillas que tras poner la dirección de la página enlazada. Si se comete este error, además de no funcionar el enlace, es posible que desaparezcan otros elementos de la página al visualizarla. Páginas en otros directorios
Quote Puedes conocer mis <a href="varios/hobbies.html">hobbies</a> vemos, para separar el nombre del directorio del nombre del archivo se usa el símbolo “/”. También se usaría, si fuese necesario, para separar varios directorios. Enlaces externos Algunos diseñadores web recomiendan que no se creen enlaces externos desde la página principal o home page de nuestro sitio Web para no incitar al visitante a que se vaya de la página. La creación de uno de estos enlaces es muy similar a la creación de los enlaces locales. El único cambio radica en que el valor dado al atributo ‘href’ es la dirección completa de Internet, sea otra página web, una imagen o cualquier otro archivo. Por ejemplo, para incluir un enlace desde cualquier página a la de DMOZ (Open Directory Project). Para ello puede emplearse:
Quote Enlace a <a href="http://www.dmoz.org">DMOZ</a> Así de fácil. Para referirse a un archivo específico del servidor de DMOZ hay que especificar la ruta de directorios y el nombre del archivo. Un ejemplo de uso podría consistir en construir un enlace a la sección sobre Internet de este buscador. Para ello hay que incluir el siguiente link:
Quote <a href="http://www.dmoz.org/Computers/">Computers</a> Un aspecto destacable de este ejemplo es que se ha especificado la ruta de directorios pero no el nombre del archivo. Con ello se consigue acceder al archivo por defecto de ese directorio. Todos los servidores web tienen un archivo por defecto de manera que si no se introduce el nombre ninguno ese archivo será el mostrado. En la mayoría de servidores el nombre elegido es index.html por lo que la dirección usada antes sería equivalente a:
Quote http://www.yahoo.com/computers/internet/index.html
(Tomado de http://lawebera.es )
Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
CSS para principiantes Para este y tutorial sólo necesitas un navegador y un editor de texto. Si el editor tiene resaltado de sintaxis CSS pues mucho mejor. Si usted está acostumbrado a usar Dreamweaver déjelo un momento aparte pues nada se compara a controlar el código de manera directa. Cascading Styling Sheets (Hojas de Estilos en Cascada) es uno de los grandes avances en la creación de páginas y programas Web. Uno de los aspectos más importantes de CSS es que no sólo maneja los estilos y tipografía sino también la distribución espacial del contenido de las páginas. Si durante años ha usado HTML y el tag table y siente que no hay necesidad de cambiar debo decirle que está en un error. En cuanto pruebe la potencia y sencillez de CSS se convertirá en un entusiasta. Además, las páginas hechas en CSS son más rápidas y ligeras, y se colocan mejor en los buscadores pues a Google y a Yahoo! les gusta lo hecho con CSS. Además, ahorrará muchas horas de trabajo, su jefe creerá que usted tardo días para cambiar el diseño de un sitio pero en realidad solo fue necesario hacer algunos pases mágicos por la hoja de estilos a la hora de la comida. Lo primero en CSS
Quote <html><head> <title> :: Mi primer CSS :: </title> <meta http-equiv="Content-Style-Type" content="text/css" /> <link rel="stylesheet" href="estilos.css" type="text/css" /> </head> <body> <p><span class="slogan">Parrafo sin acentos</span></p> <p><span class="titulo">Otro parrafo sin acentos</span></p> <p><span class="titulo">Este es un <span class="slogan">tercer parrafo</span> sin acentos</span></p> <h1>Este es el tag h1</h1> </body> </html> Note que después del tag </title> están las indicaciones para que la página HTML “jale” el diseño CSS. A continuación, cree un archivo en blanco y guárdelo en el mismo directorio con el nombre estilos.css. Comentar la hoja de estilos
Quote /* Clase para el slogan */ .slogan { color: #097a19; font-size: 14pt; font-weight: bold; font-family: Verdana, Arial, Helvetica, sans-serif; text-align: center; background-color: #b4b4b4; } /* Clase para los titulos */ .titulo { color: #d3a900; font-size: 11pt; font-family: Arial, sans-serif; text-align: left; } /* Mi versión de h1 */ h1 { color: #dd1010; font-size: 18pt; font-family: Arial, sans-serif; text-align: center; } Las clases que uno crea comienzan con un punto (.) mientras las predefinidas (como h1) no lo tienen. Note además que el código CSS se escribe con minúscula pues así lo exige el estándar. El tag SPAN sirve para marcar bloques de texto. Un bloque span, como vemos en el tercer párrafo, puede colocarse dentro de otro bloque SPAN. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Gestión de Contenidos en Portales Web 1-ra parte Información Def. Portal web: Pero, ¿qué es un Portal Internet? Podemos entenderlo como una aplicación web que gestiona de forma uniforme y centralizada, contenidos provenientes de diversas fuentes, implementa mecanismos de navegación sobre los contenidos, integra aplicaciones e incluye mecanismos de colaboración para el conjunto de usuarios (comunidad) a los que sirve de marco de trabajo. Todo esto en un entorno web. Al principio de la era internet era muy frecuente que los propios gestores de los portales (los famosos WebMasters) fuesen los que las alimentaban de información. Conforme la red ha ido evolucionando, ésta se ha convertido en un elemento cada vez más importante para todo tipo de organizaciones (algo estratégico para muchísimas de ellas), y el esquema del WebMaster-EncargadodeContenidos ha ido dejando de ser útil, o más bien se demostró que no era un mecanismo adecuado para la gestión de contenidos, pero ¿por qué? Muy sencillo, la cantidad de datos a publicar y gestionar ha crecido tanto (se habla de la explosión de los datos) que el anterior modelo se convirtió en un cuello de botella, y no sólo por la velocidad de incorporación de información a los portales sino porque los datos empezaban a requerir cada vez más atención (mantenimiento). ¿La solución a esto? Distribuir la redacción o gestión de contenidos entre varias personas y habilitar mecanismos para que éstos puedan incluirlos en el portal mediante Flujos de Publicación. Los portales web han ido evolucionando no sólo por la cantidad de datos que contienen. Poco a poco se ha pasado de modelos basados en páginas estáticas a aplicaciones web de alta complejidad que gestionan contenidos en múltiples idiomas, integran aplicaciones de colaboración entre los usuarios, proporcionan contenidos en diversos formatos para diferentes dispositivos, y un largo etcétera. Todos estos requisitos nos llevan a que los contenidos que gestiona un portal deban de ir acompañados de una gran cantidad de información de control que nos ayude a gestionarla de forma correcta. Esto lo veremos con más detenimiento en la sección de Caracteres de Control. Flujos de publicación De hecho un típico esquema para este trabajo es el que se da en la llamada ‘publicación en dos pasos’ en los que tenemos varios perfiles de usuarios:
 • Publicadores o Supervisores. Es frecuente en muchos portales que antes de publicar contenidos en un portal, éstos sean revisados por personas de cierta responsabilidad en la organización que se encargan de revisar que la información a publicar es correcta, tanto en contenido como en forma, y que es adecuada para la organización.
 Esto nos lleva a necesitar entornos de gestión de contenidos, de los que se muestran algunas pantallas esquemáticas a continuación, en las que se gestionan los flujos de publicación: redactar, guardar lo redactado para ir seguir trabajando en ello más adelante, finalizar la redacción de un documento y solicitar su publicación, revisar, volver a redactar aquellos contenidos que no hayan sido aprobados, publicar, etc.
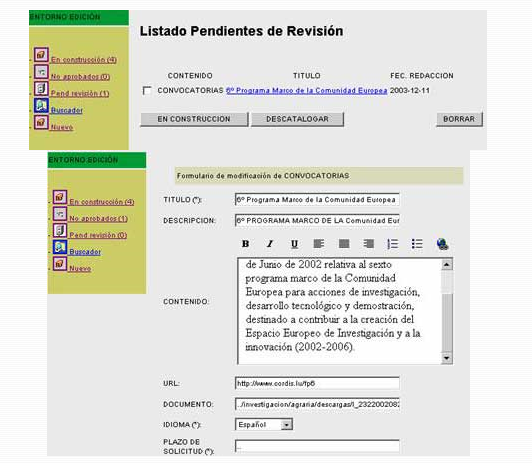 Pongamos un ejemplo, en un portal con este mecanismo ya no es el administrador del portal el que se encarga de añadir contenidos, sino que son los redactores los que asumen ese trabajo que es completado mediante el visto bueno de los Supervisores, que son en definitiva los que publican la información para que sea accesible al usuario. Caracteres de Control En cualquier portal de mediana complejidad existe toda una serie de caracteres externos que nos ayudan a gestionar los contenidos de una forma eficaz, como por ejemplo: • Idioma en el que se encuentra dicho contenido.
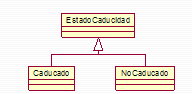
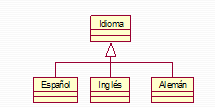 • Fecha de caducidad. Una forma fácil de gestionar de forma automática la información que ‘caduca’ es decir aquello que al llegar a cierta fecha deja de tener validez o interés para el usuario consiste en asignar a cada contenido que sea caducable (por ejemplo la información de un evento) una fecha de caducidad, de tal forma que el portal no muestre al usuario ningún contenido cuya fecha de caducidad sea menor o igual a la actual. Los contenidos caducables podrán por tanto estar ‘Caducados’ o ‘NoCaducados’.
 • Temáticas o áreas asociadas al mismo. Todos los portales suelen categorizar su información, siendo este un mecanismo que ayuda a presentar al usuario la información que le es más pertinente. Un ejemplo para las normativas: locales, autonómicas, nacionales, europeas e internacionales.
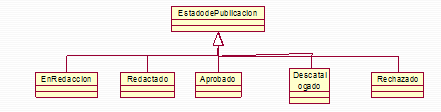 Es más, estos caracteres de control, pueden aplicarse a cualquier contenido de un portal.
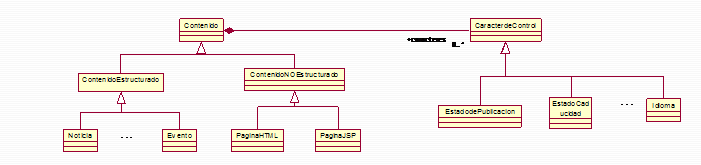 Como hemos modelado en el diagrama anterior, podemos diferenciar básicamente entre dos tipos de contenidos: Bueno, pues debemos también tener claro que no sólo los contenidos estructurados tienen asociados caracteres de Control, los contenidos no estructurados también los pueden tener. Esta cuestión la analizaremos en el siguiente punto. Espacios de Contenidos Conceptualmente se llega a un punto en el que es necesario fragmentar ese todo, y hacerlo más manejable. En el contexto de la base de datos, ya contamos con diversos mecanismos para realizar esta tarea de forma natural. Lo habitual es tener varias tablas de base de datos y usar una (o más) para cada tipo de información. Sin embargo, ¿qué podemos hacer con los contenidos estáticos y la relación entre estos y los dinámicos? El concepto que podemos desarrollar aquí es el de ‘Espacio de Contenidos’ entendiéndolo como: un conjunto de contenidos (por simplificar sólo consideremos las páginas estáticas) que comparten características comunes como el rol que desempeñan en el portal, su temática, idioma, configuración visual, ubicación física, etc.
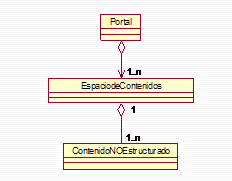 Los Espacios de Contenidos nos facilitan dos cosas:
 Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Gestión de Contenidos, un enfoque independiente 2-da parte Definición de Gestión de Contenidos En el siguiente artículo os voy a comentar en qué creo que consiste la gestión de contenidos y cómo las empresas se pueden favorecer de ello, comentando también los que considero "grandes errores de las empresas, en la implantación de soluciones de gestión de contenidos". Definir gestión de contenidos, puede ser un poco pretencioso por mi parte pero vamos a ver si entre todos los conseguimos: "Todos los procedimientos y procesos involucrados en el agregación, transformación, catalogación, agrupación, autorización, presentación y distribución de información útil para nuestros propósitos" Bueno, como podemos observar dentro de esta definición todo cabe y cuando vemos las distintas herramientas, cada una de ellas se puede centrar en distintas problemáticas: • Gestión documental: Más orientado a la catalogación y recuperación de contenidos grandes (documentos) Nosotros vamos a analizar, de un modo simplista, cuales son los procesos asociados a esta tecnología. Reduciremos a tres, las capacidades de los sistemas de gestión de contenidos: • Adquisición de Contenidos
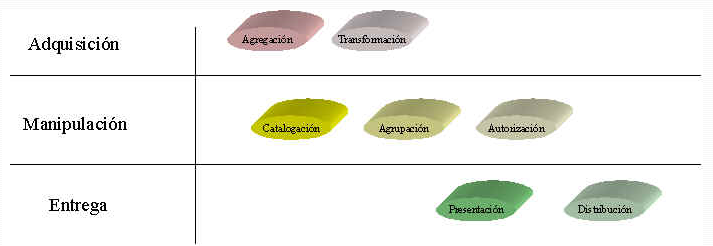 El elemento vital y núcleo del sistema será el almacén o repositorio de contenidos (considerando, a partir de ahora, un contenido como cualquier información que queremos almacenar de modo estructurado), donde la información se encuentra estructurada de tal modo que permita ser manipulada y explotada con facilidad. Este repositorio será normalmente una base de datos y tal como evoluciona la tecnología, lo ideal sería una base de datos nativa XML. Normalmente, un problema complejo es la suma de muchos problemas simples. Vamos a analizar cada problema por separado y tratar a su vez de sub-dividirlo. Adquisición de Contenidos Es posible que algunas herramientas ya integren ciertas estructuras que son bastante comunes en cualquier sistema: Noticias, encuestas, productos, etc.. pero en este caso, si no entendemos bien el concepto, es posible que caigamos en un error bastante común y es decir: "como no nos gusta cómo realizamos las tareas hasta ahora, compramos una herramienta y nos adaptamos a ella". NO, "las herramientas deben permitir optimizar los procesos de negocio y adaptarse a ellos y no al revés", nuestra empresa no debería adaptarse a una herramienta de propósito general (aunque sí podría ayudarnos a organizar ideas). Este error se comete con mucha frecuencia con las herramientas de CRM. Es evidente que posteriormente hay que alimentar de datos estas estructuras. Ya podemos hablar entonces de: Agregación Si los contenidos son propios, debemos tener en cuenta algunos temas: Si los contenidos son de terceros, debemos tener en cuenta: En cualquiera de los casos, tenemos que conocer el ciclo de vida de la información: Algunos Ejemplos: • Web financiero de información sobre cotizaciones: Sistemas centrados en la adquisición de contenidos de recepción contratada: • Agregador de ofertas: Sistema centrado en la adquisición de datos de distintas fuentes en función de peticiones: Transformación Si los contenidos son de propia creación, esto puede no ser un problema cuando el usuario introduce los datos por el propio sistema pero ¿y si nos envía un documento Excel, Word, etc.? Es evidente que hay que extraer la información y mapearla a nuestras estructuras nativas. Realizar esta labor de un modo manual, tendría un coste operativo insostenible. Si los contenidos son adquiridos de sistemas externos, por ejemplo, otros Webs (pensad en un agregador financiero donde se puede consultar nuestras cuentas en distintos bancos, centralizadamente desde un soloWeb) cualquier cambio en la estructura de origen debe ser identificado y adaptado, independientemente de tener que adaptar las estructuras de información de las distintas fuentes. La programación manual de cada transformación obligará a tener un equipo sólo dedicado a esta tarea. Existen productos que gráficamente nos permiten conectarnos a distintos sistemas y programar las transformaciones y validaciones básicas (y a veces, no tan básicas). Manipulación de Contenidos Imaginad que adquirimos de proveedores de noticias los textos (en chino), sólo los textos, pero somos famosos por tener el Web con las noticias y fotos más impactantes.... Obviamente necesitamos: Pero también podemos poner otro escenario, imaginad que el CEO de una empresa quiere introducir la nota de prensa que posteriormente se mostrará por distintos canales cuando se hagan públicos los resultados de la empresa. En este caso, necesitamos algunas cosas más: Resumiendo necesitamos ciertas capacidades: Tened en cuenta que hasta ahora no hemos hablado absolutamente nada de presentación de la información. La tratamos como algo abstracto. Será la base de nuestros sistemas de presentación. Aquí es donde difieren las distintas herramientas y donde se producen las confusiones sobre las capacidades de los gestores de contenidos. Entrega Seleccionar los contenidos de un modo sencillo ( o introducirlos directamente) y proporcionar servicios básicos (chats, foros, encuestas) Nos interesa menos la capacidad de presentar contenidos y más la de estar seguro que ha seguido un Workflow • Fomentar el consumo de productos (Compra): Orientado a fidelización (ejemplo: Web de venta directa) • Reaprovechar los contenidos en múltiples canales: Orientado a reutilización (ejemplo: Periódico con versión electrónica y el papel) Nos interesa que los mismos contenidos sean publicados en distintos medios, con el mínimo esfuerzo. Bueno, está claro que no todos los sistemas son iguales por los que tampoco podemos pretender que todas las herramientas puedan ser igual de provechosas para todos los clientes. Cualquiera que sea nuestro objetivo, siempre deberíamos poder controlar: Tampoco debemos olvidar que hay veces que los contenidos que poseemos no queremos entregarlos cuando el cliente accede al sistema sino que queremos realizar una entrega pro-activa, es decir, le enviamos contenidos de reciente publicación. Normalmente se habla de entrega multi-canal: Wap, e-mail, sms, etc Presentación Los sistemas de presentación suelen funcionar del siguiente modo: Está claro que necesitamos poder definir las plantillas de página y de componente, así como de poder localizar y asociar los componentes. Esto podría ser el primer paso pero no debemos olvidar que cuando definimos una inversión tecnológica, esta debería estar motivada por la reducción del coste, la mejora del tiempo de explotación (time-to-market) y la mejora de servicio a cliente. Para que estos tres puntos puedan cubrirse se requiere una correcta explotación de los sistemas para conocer a nuestros clientes y ofrecerles un trato personal. Requerimos de personalización .... La personalización puede ser explícita o implícita, es decir, en base a datos sobre preferencias indicadas por el usuario o en base a nuestro análisis de sus hábitos de navegación y consumos. En este caso necesitamos registrar (trazar) el comportamiento del usuario y ser capaz de ofrecer dinámicamente contenidos de categorías concretas. Pero nunca se puede olvidar una cosa, el perfil del cliente cambia con el tiempo por lo que nuestros sistemas deben ser sensibles a estos comportamientos. Aquí entran en juego otros elementos como son el análisis de datos y la definición de contenidos asociados a segmentos de usuario, es decir, CRM analítico y CRM operacional. Cuando los Webs tienen un número alto de visitas, los problemas con los que nos enfrentamos son más complejos. Un sistema de presentación como el que hemos comentado con unas pocas tablas de base de datos y un poco de imaginación, lo podríamos resolver pero .... funcionaría con 100.000 peticiones diarias. ¿Qué infraestructura necesitaríamos para dar soporte a este sistema?. Es posible que necesitemos un mecanismo un poco más complejo de composición dinámica de sistemas de presentación pero que se comporte en ciertos casos como si fuera estático. Para esto hay algunas opciones: Para que estos mecanismos sean efectivos, debemos conocer muy bien el ciclo de vida de todos los contenidos presentados en una página así como los mecanismos tecnológicos de los que disponemos. Distribución Los contenidos, pueden ser mostrados en nuestro sistema o entregados a otros sistemas (bajo demanda o de modo pro-activo). Es posible que nuestro sistema tenga la capacidad de agregar, transformar, categorizar y empaquetar los contenidos y que otras empresas quieran centrarse en su negocio y olvidarse de estas tareas y simplemente agregarlos a sus sistemas de presentación. Un ejemplo pueden ser las grandes proveedoras de noticias que se encargan de recopilar datos de multitud de fuentes y proporcionarlas a multitud de destinos (que no tienen interés ni recursos en hacerlo). Se suele hablar de sindicación de contenidos. Plan de implantación de soluciones de Gestión de Contenidos Errores comunes Comprar una herramienta (de cualquier tipo) y pretender que en pocos meses esa solución habrá resuelto todos nuestros problemas puede parecer cuanto menos que: Si una gran organización (empresa) tiene 20 Webs y queremos unificar criterios .... hay que arreglar algo más que la tecnología. Probablemente halla que modificar muchos procesos internos así como reeducar a mucha gente. La consolidación de estrategias de gestión de contenidos, requiere la madurez e involucración de distintas áreas de la empresa: Los proyectos de gestión de contenidos, para mi gusto, no se deben abordar a lo ancho, es decir, tratar de resolver 20 problemas grandes al mismo tiempo. Implantación de solución: Riesgos a Evitar Otras consideraciones Comentario final
(tomado de http://programacion.com/ )
Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Comandos útiles en línea de comandos Lista de comandos útiles que podemos utilizar en nuestro PC. En Windows XP hay muchisimos comandos útiles, pero lo malo de todo esto es su gran desconocimiento. Para poder utilizarlos, debemos abrir la consola de comandos, o la ventanita de MS-dos. En Windows XP, por ejemplo, podemos acceder a ella clickeando en: Inicio –> Ejecutar –> cmd o bien pulsando la tecla “Windows + R” Con todos estos comandos, también podemos solicitar una ayuda, añadiendo uno de los siguiente parámetros: /? - /h a nuestra llamada. Comandos de Archivos y sistemas de ficheros Comandos de Configuración e información del sistema Comandos de Redes Comandos Miscelánea Comandos de Microsoft Management Console (MMC) Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Las etiquetas HTML más raras Disponemos de un gran número de etiquetas HTML pero a menudo utilizamos sólo un pequeño porcentaje, no siempre con un "<div>" o con un "<span>" podemos solucionar todos nuestros pequeños problemas de HTML. Vamos a ver 10 etiquetas raras, algunas de estas etiquetas no las conoceréis pero otra seguro que las usaт a menudo, personalmente no conocía algunas... <abbr>, <address>, <acronym>. Las 10 etiquetas más raras 1. <wbr> 2. <abbr> 3. <label> 4. <ins><del> 5. <address> 6. <acronym> 7. <optgroup> 8. <cite> 9. <fieldset> 10. rel Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
13 leyes de oro para dar el gran paso a XHTML Amigos, aquellos que están decididos pero no saben cómo entrar en el mundo XHTML, este post quizás les aclare algunas cosas. El gran paso al mundo XHTML es simple: las reglas. En todo lenguaje encontraréis reglas básicas. XHTML no es un lenguaje distinto a HTML, para nada, sólo tiene unas reglas básicas que lo hacen especial. Esas reglas te permiten hacer páginas válidas. Que una página sea válida no asegura que sea buena o que solucione todos los problemas. Para ello, lo mejor es estudiar el propósito de cada etiqueta. Esto nos permite discernir que etiquetas debemos utilizar. Esto (las reglas y los propósitos) nos permitirán no sólo crear estupendos ejemplos de código (simple, semántico y accesible) sino también páginas que validan, son fáciles de mantener y re-utilizar. Volviendo al primer escalón de nuestro gran paso… las reglas, ¿Dónde están las reglas? En cualquier lenguaje pueden averiguar comprando un manual, o bien, yendo a la página oficial. Para XHTML basta con acercarse a la web de W3C y buscar dicha especificación. W3C te ofrece muchas especificaciones de XHTML. Tanto de las versiones 1.0 como 1.1, 2, básicas, por módulos, etc. No hay motivos para asustarse al ver tantas opciones. Les explicaré la razón de ello. XHTML no es un invento nuevo del HTML. Es una mejora, una revisión de lo que se hizo en el pasado. Los científicos y desarrolladores que colaboran en estos proyectos van mirando las necesidades y las nuevas posibilidades de estos lenguajes, creando así nuevas versiones con reglas cambiadas. Como HTML no satisfacía dichas condiciones, se creó XHTML, que es HTML pero con reglas principales de XML. XML es un lenguaje tan abierto y mutante que necesita reglas. Esas reglas básicas se aplicaron a HTML dando por creado XHTML. XHTML no deja de ser un HTML con unas reglas más estrictas que permiten una cierta uniformidad a la hora de hacer cosas. Esta uniformidad asegura a cualquier fabricante un margen o unos límites para sus herramientas (Ej. Un navegador). Imagínense que HTML siga siendo un lenguaje anárquico, que existan miles de etiquetas provenientes de muchos lados en donde existen reglas. En estas condiciones, no habría uniformidad, no existirían patrones de los cuales los fabricantes se puedan coger para hacer una herramienta que muestre, analice y aproveche el HTML, sino que sería el caos (muy lejos de eso no estamos todavía). Entonces, primero las reglas. XHTML tiene unas reglas muy básicas. Citaré paso a paso las reglas del XHTML: Regla 1: Todos los documentos XHTML necesitan especificarse con un DTD Metáfora aplicable: Sin DTD, la página no valida. El navegador no sabe que tipo de documento mostrará al usuario, por lo que estará a la expectativa poniendo todo su motor y esfuerzo para mostrar el documento bien… eso lo podemos traducir en: más trabajo para el navegador. Regla 2: El elemento raíz de cada documento deberá ser la etiqueta <html> Además, la etiqueta <html> requiere de dos atributos importantes: los idiomas. Como todos los documentos tienen que llevar un idioma especificado, éstos deben anunciarse en la primera etiqueta utilizando los atributos xml:lang="…" y lang="…" a la vez. xml:lang="…" servirá para aquellos navegadores o dispositivos (Ej. Un teléfono móvil) que soporten atributos en XML (recuerden que, XHTML es básicamente el HTML que se quiere convertir en XML). Entonces, hemos de poner este atributo que no existe en el mundo HTML pero si en XML. Luego, debemos invertir golpes de tecla en otro atributo que sí pertenece al mundo HTML y es el atributo lang="…". Este atributo ayuda a especificar en qué idioma estará escrito el documento, de la misma forma que lo hace xmlang pero escrito a la HTML. Regla 3: Los documentos deben ser gramaticalmente correctos Por ello, aplicaremos una política kosher para hacer nuestros documentos XHTML. Debemos tener en cuenta muchas cosas al escribir XHTML porque como había comentado anteriormente, los documentos son más estrictos que HTML y no nos dejan por ejemplo pasar siquiera la utilización de mayúsculas en las etiquetas de XHTML. Los documentos tendrán que tener una característica de escritura y estar bien anidados. Anidados es otro término que confunde hasta el más experimentado en el tema. Creedme que hasta el más entrenado a veces se olvida de cerrar elementos de HTML o XHTML. Para ello, en XHTML esta regla es la más estricta de todas, no se puede uno pasar por alto nada, si empieza con una etiqueta, se debe cerrar al terminar de utilizar. Esto en HTML no es problema porque muchas equiquetas permiten el no cierre (Ej. <p>) pero en XHTML no. Un ejemplo correcto: Como vemos en el ejemplo, hemos comenzado con la etiqueta <p> luego en medio con <em>, terminamos de usar <em> y lo cerramos con su correspondiente </em> que luego terminamos cerrando todo con la etiqueta </p> que antes habíamos usado con <p>. Un ejemplo mal hecho: Aquí notarán que algo no cuadra, si empezamos con <p> y luego abrimos otra etiqueta <em>, para cerrar bien debemos primero cerrar la segunda (la <em>) y no la primera. Usando </em> antes que </p> y luego sí </p>. Otro caso común y que a cualquiera le puede pasar: Aquí el error está dentro del mismo texto. Hemos hecho bien la primera parte (abrir y terminar el párrafo con <p> y </p> pero dentro hemos abierto con <i> y cerramos con </b>. Ahí está el problema. Debería ser: Abrimos con un <b> y cerramos con un </b>. Dentro de <b>...</b> lo mismo, abrimos un <i> y cerramos con un </i>. Debido a la naturaleza de <b> e <i> éstos pueden ir en el orden que queramos: primero el <b> o el <i>. El resultado será siempre el mismo siempre y cuando se encuentren bien anidados. Ojo con anidar elementos que no son propios de su naturaleza o los resultados serán desastrosos. Más adelante hablaré de la naturaleza de cada etiqueta. Regla 4: Los nombres de elementos y atributos deben escribirse en minúscula Regla 5: Todas etiquetas que no sean vacías deberán cerrarse Ejemplo: Regla 6: Los valores de los atributos deben ir entre comillas dobles (importante) Antes podíamos escribir cosas como estas: Ahora debería ser así: Regla 7: Minimización de atributos Esto no funciona en XHTML, deberías escribirlo como: Regla 8: Elementos vacíos deben llevar una barra de cierre Bien hecho: Mal hecho: Nótese la barra al final de la etiqueta "/>". También podemos verla en la etiqueta <hr> de esta forma <hr />. ¿Por qué el espacio entre la barra y el nombre de etiqueta? Por motivos de compatibilidad con navegadores viejos. En un futuro, no hará falta. Regla 9: Elementos con atributos id y name Otro factor importante que siempre se me pregunta en las charlas, curso que imparto son, ¿qué diferencias hay entre name y id? Bueno, name especifica lo mismo que id solo que id es único en todo el documento. Es una forma de decir este es la única etiqueta con este valor sirve para diferenciar una etiqueta de otras iguales. En XHTML 1.0 transitional los valores que tengan name deberán incluirse un id: En XHTML 1.0 estricto o XHTML 1.1 los valores que tengan name deberán ser id: Bajo ninguna causa pueden llevar name. id al ser único, no puede repetirse este valor, o sea: Los name pueden llevar números y letras indistintamente. Los id también pero deberán comenzar con una letra de la a - z ó de la z - a y luego números. Si esto se olvida el documento no valida y los resultados pueden ser no deseados. Regla 10: Conocer los elementos de bloque, linea y reemplazados Los elementos de bloque son todos aquellos que en su estado natural ocupan toda una línea de pantalla, y desplazan hacia abajo a otros elementos de bloque, linea o reemplazados. Los elementos de linea son todos aquellos que puestos en su estado natural se agolpan uno al lado del otro y se desplazan hacia abajo cuando el ancho de la pantalla no les deja hueco donde acomodarse. Los elementos reemplazados son todos aquellos que un día fueron algo y hoy por determinada causa no lo son. Si una imagen (elemento en linea) gracias a una propiedad escrita en CSS pasa a ser un elemento en bloque, este no es un elemento en bloque sino un elemento reemplazado que cumple las características de un elemento en bloque. Aprenderse qué elementos son de linea o bloque es una tarea esencial para no cometer errores. En la siguente regla explico porqué es importante. Regla 11: No todos los elementos pueden ser anidados por otros elementos y viceversa Por decirlo así, no debemos caer en ciertas irregularidades como: Un elemento de línea que encierre a un elemento de bloque: Mejor así: Debéis tener sumo cuidado con el anidado. Esto se puede solucionar sabiendo qué elementos estáis usando, si son de línea, si son de bloque, etc. Regla 12: Aprenderse para qué sirve cada etiqueta Como podrán observar, quieren reemplazar a una etiqueta importante como lo es <h1> por una de menos importancia como lo es <span>. <h1> sería la etiqueta correcta para aplicar a un título en una página y, con el uso debido de CSS se puede obtener el mismo resultado y con mejores prestaciones que usando <span>. <span> es una etiqueta muda e invisible en el mundo HTML, sirve para crear elementos de línea con determinada </p> función de CSS pero no para definir la estructura de un documento. Otro caso me lo ha enviado una lectora que está trabajando en un proyecto que requiere el traspaso del antiguo HTML a XHTML: Aquí está claro, quieren reemplazar el viejo <b> (que sigue siendo válido pero a futuro no lo será) por una etiqueta <div id="negrita"> que tiene como intenciones reemplazar a la etiqueta <b>. En este caso lo correcto sería utilizar la etiqueta <strong>, porque es buena para marcar palabras y resaltarlas, tanto visualmente como auditivamente. <strong> cumple más funciones adecuadas para este caso que utilizando <span>, <div> u otra etiqueta que visualmente no se delate. Sumo cuidado con estos cambios. Regla 13: Que una página valide no significa que ¡ya está todo dicho! Un caso válido pero mal aplicado: Esto puede validar perfectamente pero: Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Hola y bienvenido al foro de uCoz.
Para modificar tu codigo tienes que ir a Inicio » Gestión de diseño Post editado por sorin - Viernes, 2009-07-17, 11:42 PM
|



| |||