
| Moderador del foro: ZorG |
| Foro uCoz Ayuda a los webmasters Configuración del diseño Primeros pasos para aprender a hacer una página web |
| Primeros pasos para aprender a hacer una página web |
PRIMEROS PASOS PARA APRENDER A HACER UNA PÁGINA WEB
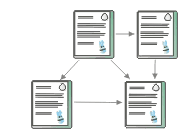
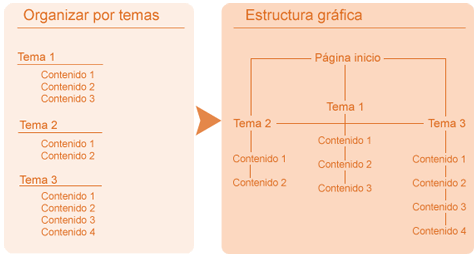
Antes de nada, decir que el desarrollo web es un proceso creativo y personal en el que cada uno decide cómo hacer las cosas, por lo que estos pasos que te propongo aquí son sólo eso, propuestas, ideas, sugerencias o como quieras llamarlo. Cada uno después puede optar por hacer las cosas como prefiera. No obstante, puede ser interesante que visites las secciones accesibilidad, usabilidad y posicionamiento en buscadores antes de comenzar a elaborar tu trabajo, ya que cuando las leas comprenderás que hay que tener muchas cosas en cuenta a la hora de elaborar una web y sus contenidos si queremos tener cierto éxito. Una vez aclarado esto, hay que decir que para el diseño de páginas web debemos tener en cuenta varias etapas: 1. Planteamiento de objetivos para tu página web Esta etapa es muy importante y con frecuencia se pasa por alto. Se trabaja en el papel para plantearnos el proyecto y qué queremos conseguir al realizar nuestra web. La planificación de tu web debe incluir: • Breve descripción de los contenidos de la página, su título principal, etc. 2. Estructurar el contenido de la página Es conveniente que dibujemos un organigrama con todas las partes del sitio web, distribuyendo el texto, los gráficos, los vínculos a otros documentos y otros objetos multimedia que se consideren pertinentes, mediante el cual ir creando la estructura de la página web. Antes de empezar a desarrollar tu página web en el ordenador, debes tener muy claro cuáles serán sus contenidos, su estructura, el nombre de la página, etc. cosas que no se deben hacer sobre la marcha para evitar rectificaciones innecesarias, trabajo inútil y pérdidas de tiempo. Hay varias maneras de estructurar el contenido de una web: En lista: Esta estructura es la opuesta a la anterior. En ella no existe página principal ya que todas están en el mismo nivel. Para llegar a la última página hay que recorrer todas las anteriores. Es una estructuración muy adecuada para la presentación de manuales o aplicaciones donde el usuario deba recorrer forzosamente una serie de páginas web para conseguir su objetivo. Mixta: Esta estructura es una combinación de las dos anteriores. Las páginas están jerarquizadas en niveles, los cuales a su vez están conectados entre sí en forma de lista. Esta estructura es mucho más navegable y práctica, puesto que permite poder desplazarse de rama en rama sin necesidad de volver a la página principal para hacerlo. En red: Esta estructura supone que todas las páginas de la web están conectadas entre sí, por lo que es una estructura más compleja y menos ordenada. Su ventaja es que desde cada página podemos ir a cualquier otra del sitio. No obstante, requiere mucha planificación para evitar ofrecer al visitante un caos de enlaces innecesarios. Una vez tengas claro lo que quieres hacer y su estructura básica puedes empezar a recopilar información para confeccionar cada sección de tu página web. Conforme vayas investigando sobre el tema de la web, casi con seguridad irás realizando modificaciones tanto en su estructura como en sus contenidos para adaptarla mejor a lo que has aprendido, por lo que es conveniente que trabajes sobre borradores, no con versiones definitivas, te ahorrarás mucho trabajo. Por ejemplo, puedes haber decidido hacer una web sobre Ferrari, y en cuanto a su diseño querer colocar un menú a la izquierda con las secciones principales, un cuerpo central con el contenido de la sección y una última columna a la derecha donde insertar tu publicidad. No obstante, puede ocurrir fácilmente que al buscar información sobre su escudería encuentres tanta y tan diversa que llegues a la conclusión de que es más cómodo para los visitantes colocar un menú de navegación específico de la sección en la izquierda y el principal en la derecha para que puedan navegar por la sección con rapidez. Por lo que si ya hiciste la página definitiva de la sección llamada escudería, tendrás que retocarla para adaptarla a tus nuevas necesidades, lo que supone un gasto de tiempo y esfuerzo innecesario. 3. Diseñar la página web Una vez tengas hecha la estructura, recopilada bastante información y completado el contenido de varias secciones, tienes suficiente material como para saber con más precisión lo que quieres, por lo que puedes empezar a diseñar gráficamente cada una de las páginas de tu web, indicando los elementos interactivos y gráficos que van a intervenir en cada una. Para esto, y fundamentalmente para manejar los vínculos entre documentos, se creó el lenguaje HTML. El HTML es un lenguaje de marcación diseñado para estructurar textos y presentarlos en forma de hipertexto, que es el formato estándar de las páginas web. A la hora de empezar con el diseño, ten en cuenta que: • La estructura de la página debe ser lo más lógica posible facilitando la navegación a tus visitantes (es importante en este punto la usabilidad). Ninguna página puede quedar huérfana, es decir, todas las páginas deben de tener enlaces a otras páginas. Si esto ocurre, es probable que el usuario cierre nuestra página y entre en otra en la que le sea más fácil navegar por los contenidos. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Crear la página web. Consejos
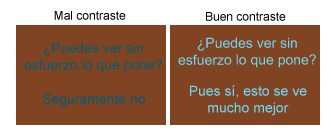
Tips iniciales para hacer una página web Hay algunas ideas que se deben tener en cuenta a la hora de ponerse a diseñar la página web. Algunos consejos: Usa CSS (hoja de estilos) Separa el contenido del diseño de tu web usando hojas de estilos (CSS). Es mucho más fácil editarlo después, les gusta más a los buscadores, y las páginas cargan más rápido. La era de las tablas ha muerto. Simplifica La web soporta multitud de formatos, desde imágenes animadas, hasta sonidos, presentanciones en flash, videos… Todos estos recursos deben usarse con cautela, si recargas la web con gifs animados o le pones un sonido que tus usuarios no puedan quitar si así lo quieren, es muy probable que se marchen. Es mejor optar por un diseño sencillo que recargarlo en exceso. Enlaces correctos Usa palabras que indiquen claramente a donde dirige el enlace, no pongas cosas como “click aquí” o “este sitio”, el visitante no sabrá a donde va. Diferencia claramente qué es un enlace de lo que no lo es poniendo un color diferente al texto del enlace, así tus usuarios podrán localizarlos con rapidez y visitarlos si les interesa. Crea listas de ideas, párrafos, frases en negrita y en cursiva, subapartados y cualquier otra cosa para diferencias partes en tus contenidos. La gente en la web lee deprisa, así que procura que la lectura de lo más importante pueda hacerse de un vistazo rápido. Intenta usar fuentes comunes como Verdana o Arial, que casi con toda seguridad la tendrán instaladas en sus ordenadores todos los usuarios que te visiten. Si la fuente que tienes en tu web no está disponible en el ordenador del usuario, mostrará el texto con otro tipo de fuente, lo que puede llegar a desajustarte el diseño. Procura usar un color de texto y fondo que haga buen contraste para facilitar al máximo la lectura del texto de tu web. Si de por sí leer en una pantalla cansa más que hacerlo en papel impreso, imagina lo que debe ser si no distingues bien la letra del fondo. Algunos ejemplos: Fondos claros Usa fondos de pantalla sencillos o directamente no los uses. Los fondos complicados, con muchos dibujos o colores pueden distraer al usuario del contenido de tu web o incluso dificultarle su lectura. Imágenes Los gráficos son un recurso de diseño útil. Le añaden una nota de color a tu web y le permiten tomarse una pausa al usuario, pero no recargues la página con imágenes que no lleven a nada. Si pones imágenes que sirvan para algo, para decorar, para explicar algo, para poner ejemplos, etc. Optimízalas para que pesen lo menos posible y las páginas no tarden mucho en cargarse (a la gente no le gusta esperar). En relación a esto puedes leer como añadir imágenes a una web y el tratamiento de imágenes para la web. Navegación clara No les hagas al visitante adivinar donde está cada cosa o a qué página dirige cada enlace. Si el usuario no sabe a donde ir para conseguir lo que venía buscando se marchará sin pensárselo, en Internet hay miles de alternativas a tu página. Asegúrate de que los enlaces importante son bien visibles, crea un mapa web, pon enlaces importantes también en el pie de página, incluye un enlace a la página principal en todas tus páginas, etc. Compatibilidad con navegadores No hagas una web que sólo se vea en Internet Explorer. Es uno de los errores más comunes de la gente que empieza a hacer webs. Que se vea bien en un navegador no significa que se vea bien en todos, debes asegurarte que se ve correctamente por lo menos en los más importantes (Firefox, Netscape, Opera…). Para comprobarlo puedes usar herramientas como BrowserShots o instalar los navegadores más usados en tu ordenador y probar cómo se ven las páginas web en ellos. Resolución de pantalla No todos los ordenadores tienen la misma resolución de pantalla, al igual que con el tema de los navegadores, debes asegurarte de que tu diseño se vea bien a 800×600, 1024×768, etc. Revisa posibles fallos Frecuentemente debes revisar tu web en busca de posibles fallos, éstos no les gustan ni a los visitantes ni a los buscadores. Uno de los más comunes es el tener enlaces rotos (enlaces con una dirección incorrecta). Páginas en construcción No llenes el sitio de páginas en construcción. Si todavía no tienes creada una sección no la tienes, no pasa nada, pero es frustrante pinchar un enlace esperando encontrar algo y ver la típica pantalla de página en construcción, no da una buena imagen de tu web. Poner un buscador en tu web Si tu web tiene muchos contenidos o páginas, puede ser útil incluir un buscador para que tus usuarios encuentren más fácilmente lo que buscan. Es un valor adicional para tu web y mejora mucho la usabilidad. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Etapas del diseño web
Estas son algunas etapas que se sugieren para diseñar eficientemente un sitio; es conveniente no comenzar a escribir ninguna línea de código HTML antes de completar las primeras etapas. Delimitación del tema Si no se evalúa adecuadamente la cantidad de tiempo que se dispone contra la cantidad de tiempo requerida para elaborar un sitio de la magnitud deseada, el resultado puede ser desastroso. Muchos proyectos Web fracasan porque comienzan a crecer y crecer sus especificaciones, sin que haya detrás un trabajo ordenado de delimitación de contenidos. Obsérvese lo siguiente: la mayoría de los sitios que son premiados con distinciones como "Lo mejor de …", "La mejor página de la semana …", "Top 5% del Web", son sitios que se dedican a temas muy específicos. La gente no quiere un montón de sitios que tengan referencias a otros lugares, la gente lo que busca es el contenido. Recolección de la información Agregación y descripción Aplicamos una clasificación de tipo lineal a fragmentos de información que requieren que la persona que los lee vaya avanzando poco a poco en el conocimiento de algo, como en un libro. Usualmente los pondremos en una misma página, usando FRAMES o una técnica similar si se estima apropiado. Aplicamos una clasificación de tipo jerárquica a trozos de información que sean complementarios o que dependan uno de otro, como secciones y subsecciones. Usualmente los pondremos en diferentes páginas. Es importante aquí no centrarse en una única forma de clasificar los documentos. Una serie de descriptores tienen que ser definidos. Ademas, un mismo documento puede pertenecer a varios valores de un mismo descriptor. Si nos encontramos en esta etapa discutiendo sobre si un elemento de información va en una u otra parte, es que estamos cometiendo un error: debe ir en todas las partes donde un usuario razonable esperaría encontrarlo. Estructuración Metáfora A esta etapa le llamamos "metáfora" pues permite referirse a una misma entidad (en este caso, una página HTML) en diferentes contextos. Estas paginas deben ser diseñadas cuidadosamente puesto que seran importantes para los usuarios al permitirles "saltar" dentro del sitio desde zonas logicamente distantes. Diseño y estilo gráfico En cuanto a la cantidad y tamaño de las imágenes, hay que adoptar un equilibrio. Hay sitios que se basan casi por completo en grandes y lentas imágenes GIF, otros que se ven bastante pobres pues son casi sólo texto, con lo que se desaprovechan los métodos multimediales . El esquema que se adoptará, (que se encuentra en algún lugar entre ambos extremos) varía de diseñador a diseñador y es un punto importante a considerar. Otro punto importante en la etapa de definición de la parte gráfica, es intentar en lo posible mantener una cierta coherencia gráfica, y atreverse a innovar en cuanto a ella. Un color de fondo, un fondo o una distribución interesante de los elementos dentro de una página es algo que no se olvida con facilidad. Ensamble final Testeo Para esta etapa, lo mejor es tratar de buscar usuarios que vayan a utilizar el sitio en la practica, y si eso no es posible, ponerse en el lugar de las personas que vean los documentos, y seguir los pasos que suponemos que ellos seguirán.
(Tomado de http://lawebera.es )
Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Sistema de navegación de la página web
Un buen sistema de navegación es imprescindible en toda página web. Es una parte importante de la organización de la estructura de la web. Que el usuario sea capaz de moverse con soltura y facilidad por las distintas páginas del sitio, que encuentre lo que busca rápidamente, que no se pierda yendo de un enlace a otro sin saber donde está, que no quede colgado en una página concreta sin poder navegar por otras o volver atrás… son algunas de los aspectos que hay que cuidar en la navegación de un sitio web. Veamos algunos puntos importantes. La página de inicio Menú de navegación O vertical; Como mencionamos antes, para sitios web con un número de páginas pequeño puede ser bueno enlazar a todas ellas desde cada página para que el usuario tenga en todo momento la información disponible en la web a su alcance. Por ejemplo, si es una página web informativa sobre tu empresa y no tiene otra finalidad, puede que cuente con 10 ó 15 páginas en total, las cuales pueden perfectamente ser enlazadas desde cada página individual. Sin embargo, cuando una web contiene mucha información este tipo de menús tiene poco sentido, porque entonces tendríamos menús con cientos de enlaces, algo excesivamente largo para ser usable. Lo normal en estos casos es enlazar desde la página principal a las secciones más importantes, y desde cada una de ellas a sus contenidos concretos. Pie de página Evitar páginas huérfanas Enlazar siempre al índice Ruta de acceso o ¿dónde estoy? Es conveniente que cada parte de la ruta tenga su enlace correspondiente, de forma que el usuario pueda ir a esa categoría si lo desea. Sin el enlace a cada sitio, la ruta de acceso pierde sentido ya que le dice al usuario donde está pero no le da alternativas. Incluir un buscador Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Como organizar una página web. Diseño de la estructura
Llegados a este punto necesita definir la organización de la información de tu sitio web. Es decir, ha llegado el momento de crear la estructura de tu web, su esqueleto, la base que soportará todo lo demás. La forma en que estructures el contenido de tu web será determinante para que los usuarios encuentren o no lo que buscan (algo muy relacionado con la usabilidad). Por tanto, ésta debe facilitar y agilizar al máximo la búsqueda de información de tus visitantes. Al mismo tiempo, también es importante diseñar la estructura de forma que actualizaciones futuras de la web no obliguen a cambiar muchas partes de la página. Página de inicio Diseño del menú de navegación Tipos de estructuras de sitios web Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
CARACTERÍSTICAS DE LOS ROBOTS DE BÚSQUEDA Indicando a los robots de búsqueda que documentos de nuestra web deben indexar En 1993 y 1994 estos robots entraron en servidores de WWW e indexaron páginas que no debían: documentos personales, documentos confidenciales, duplicación de archivos, información temporal... Estos incidentes hicieron ver la necesidad de establecer los mecanismos necesarios para que los servidores de WWW pudiesen indicar a los robots de búsqueda las piezas a las que les estaba permitido acceder. El 30 de de junio de 1994 (robots-request@nexor.co.uk) se llegó a un consenso estándar para trata esta necesidad, alcanzándose una solución operacional. Lo que sigue no es un estándar oficial promovido por una organización oficial. No es tampoco una obligación que se tenga que cumplir, por lo tanto no es seguro que todos los robots lo sigan. Se tiene que considerar como una facilidad a lo hora de proteger aquellos documentos y archivos que queremos que no indexen los motores de búsqueda. Para hacer la exclusión se crea un archivo en el servidor que especifica a los robots de búsqueda a qué archivos no tienen acceso y se le llama robots.txt. El robots.txt es un documento sencillo de texto plano, no se debe escribir en HTML, ni incluir expresiones diferentes al estándar ya que los robots no las reconocerán. Un simple documento de texto redactado con el Bloc de Notas de Windows es lo correcto. Debe estar alojado en la raíz del sitio, justo dónde alojamos la página index. http://www.dominio.com/robots.txt El formato del archivo está constituido por líneas que indican los valores para dos campos únicos: User-agent y Disallow. Los motores de búsqueda mirarán en la raíz del domino llamando a ese fichero especial "robots.txt" (http://www.dominio.com/robots.txt). El archivo le dice al robot de búsqueda qué archivos puede indexar, a este sistema se le denomina The Robots Exclusion Standard. En caso de que no exista el fichero robot .txt el robot considerará que no hay ninguna exclusión y rastreará cualquier página del web site sin excepción. Si es necesario determinar una política de acceso para varios robots de búsqueda se incluirán tantas líneas cuantos robots necesitemos especificar. Nunca se agruparán en una sola línea. Ejemplo: User-agent: googlebot Es necesario que exista al menos un registro en el documento para que sea correcto. Disallow: Una línea en blanco para Disallow indica que todos los archivos pueden ser indexados, se escribiría así: Espacio y comentarios en blanco Disallow: email.html # recopilación del formulario Algún spider no lo interpretaría correctamente e intentaría ignorar el documento email.html # recopilación del formulario Lo mejor es poner los comentarios en líneas independientes, por ejemplo: # recopilación del formulario Un espacio en blanco al principio de una línea se permite pero no se recomienda por los mismos motivos, puede que sea mal interpretado por el spider. Ejemplos User-agent: * Para prohibir que todos los spider indexen cualquier documento User-agent: * Para evitar que todos los spider indexen nuestros directorios cgi-bin e images User-agent: * Para prohibir al spider Roverdog, específicamente, que indexe cualquier archivo del sitio: User-agent: Roverdog Para prohibir a googlebot que indexe el archivo cheese.htm: User-agent: googlebot Para indicar que ningún robot debe visitar cualquier URL que comience con "/cyberworld/map/" o "/tmp/", o "/foo.html" User-agent: * Para indicar que ningún robot debe visitar cualquier URL que comience con "/cyberworld/map/", a menos que el robot se llame "cybermapper": User-agent: * Documentos inaccesibles a todos los robots Se pueden indicar de dos maneras: User-Agent: * O incluyendo estos documentos en una carpeta llamada "norobots" y redactando el robots.txt así User-Agent: * Los documentos quedarán inaccesibles si tomamos la precaución de asegurarnos que nuestro servidor no está generando un listado del directorio norobots. Sin embargo, configurar un archivo de este tipo no es una garantía de que los documentos no puedan ser alcanzados por atacantes. Y hay que tener claro que el robots.txt es una medida de exclusión para los robots de búsqueda, no una medida de seguridad. Si los datos que contienen esos ficheros son sensibles: contraseñas de usarios, datos personales etc... lo más serio es usar además un sistema de autentificación o SSL que asegure la completa privacidad de los documentos Un ejemplo real de archivo robots.text es este: http://www.google.com/robots.txt :) Errores al redactar el robots.txt Uno de los errores más comunes es poner la sintaxis al revés: Disallow: * Debe ser: User-agent: scooter Otro error es hacer un rechazo múltiple en una línea poniendo en ella múltiples directorios como: Disallow: /css/ /cgi-bin/ /images/ Porque la mayoría de los spider malinterpretarán esa línea . Algunos intentarán buscar el directorio /css//cgi-bin//images/ o tendrán en cuenta sólo un directorio olvidándose del resto. La sintaxis correcta sería: Disallow: /css/ Línea Enders en DOS: Se tiene que editar el robots.txt en el modo de UNIX y y hacer upload siempre en ASCII. Muchos clientes del ftp harán la transformación a la línea enders de Unix automáticamente (seamlessly), pero otrosno . Un error que el estándar permite son los comentarios al final de la línea: Disallow: /cgi-bin/ #directorio privado Tiempo atrás han existido motores que buscaban la línea entera considerando # parte del nombre del directorio. Ahora no se tiene noticia de que alguno se equivoque o no pero ¿merece la pena arriesgarse en un error semejante por ahorrarnos una línea de código? El estándar no trata específicamente los espacios de más en las líneas lo considera un mal estilo de escritura, pero tendríamos que preguntarnos una vez más si merece la pena arriesgarnos a ser malinterpretados por algo tan nímio. En ocasiones el spide interpreta la página de error 404 y las páginas de redireccionamiento como un documento HTML válido . Lo más aconsejable es indicar en el archivo .txt o en los metas tags que este documento no tiene que indexarse El estándar determina que solo el User-agent y el Disallow pueden ir con mayúsculas, lo que sigue es incorrecto: USER-AGENT: EXCITE Otro error común es especificar cada archivo en un directorio como aquí: Disallow: /AL/Alabama.html Se tiene que especificar con la opción del directorio de esta manera: Disallow: /AL La barra invertida indica al spider el límite del directorio. No hay que poner nunca Allow sólo Disallow, se rechazar para no permitir. Esto es incorrecto: User-agent: Excite Esto es correcto: User-agent: Excite ¿Qué hace un spider cuándo no hay barra invertida cómo aquí? User-agent: Excite Pues que dejará de indexar cualquier extensión de archivos con el nombre cgi y cualquier directorio nombrado cgi. Otro error es poner palabras clave en el directorio robots. txt o editarlo en formato HTML. Usar etiquetas meta para autorizar a los motores de búsqueda La etiqueta META se coloca en la sección HEAD del HTML. Un formato completamente simple sería ( si queremos que no indexen los enlaces del index).
Quote <HTML> <HEAD> <META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW"> <META NAME="DESCRIPTION" CONTENT=" Esta página es......"> <TITLE>...</TITLE> </HEAD> <BODY> ... Opciones La etiqueta CONTENT tiene cuatro opciones; el indice, noindex, follow, nofollow separados por comas. INDEX especifica que se acepta incluir la web en el índice del buscador. FOLLOW especifica que se acepta que se indexen también los enlaces existentes en nuestro documento index. No es cierto que los motores de búsqueda sigan los enlaces del index por defecto, Inktomi por defecto sigue la orden índice, nofollow . Hay también dos órdenes globales que incluyen ambas acciones: all y none
Quote ALL=INDEX, follow y NONE=NOINDEX, nofollow Combinaciones posibles <meta name="robots" content="index,follow"> <meta name="robots" content="noindex,follow"> <meta name="robots" content="index,nofollow"> <meta name="robots" content="noindex,nofollow"> <meta name="robots" content="all"> <meta name="robots" content="none"> Visit-time
Quote # Permitir trabajar a los botsde 2 am a 7:45 am # Las horas son siempre Greenwitch Visit-time: 0200-0745 # Un documento CADA 30 minutos Request-rate: 1/30m # Combinado: 1 doc cada 10 minutos # y solo de una a 5 tarde Request-rate: 1/10m 1300-1659 ¿Qué es un WWW robot? ¿Qué diferencia hay entre un www robot y mi navegador? ¿Qué es un Agente? ¿Qué diferencia hay entre un www robot y un directorio? ¿Cuántas clases de www robots hay? ¿Qué es un Search Engine? Ventajas de la existencia de estos robots de búsqueda 2.860 resultados en 0, 14 segundos de búsqueda, ¿cómo no amarlo? Desventajas de los robots de búsqueda Los robots de búsqueda, con su afán de indexar, colapsaron ciertas redes en el pasado ya que cuando un www robot investiga un servidor adopta la apariencia de usuarios que visitan las web alojadas en él y cuanta más información exista en el servidor, más usuarios creará el robot para analizarla. Hoy en día existen mecanismos para que no se produzcan y la información suficiente para diseñar robots más eficientes. No hay que perder de vista que son máquinas, diseñadas con los conceptos más pluscuamperfectos del momento, pero máquinas que no son capaces de discernir entre un documento privado, un documento que sólo le interesa a mi grupo de trabajo, un borrador de una tarea pendiente, un documento temporal..... Lo indexan todo y este fue el motivo por el que se crearon los archivos "robots.txt", para indicar a los robots de búsqueda qué documentos tenían o no tenían que añadir a su base de datos. ¿Cómo decide un robot las webs qué va a visitar? La mayoría de los buscadores permiten también que se ingrese una dirección manualmente de manera que después la visite el robot para su indexación definitiva. Usan también otros recursos como listas de correo, grupos de discusión, etc. Todo esto les da un punto de partida para comenzar a seleccionar url's para visitar, analizarlas y usarlas como recurso para incluirlas dentro de su base de datos. ¿Cómo indexa un documento el robot de búsqueda? ¿Cómo sé si un robot de búsqueda me ha visitado? ¿Por qué las solicitudes al archivo robots.txt orientan sobre las visitas realizadas por los robots de búsqueda a mi sitio? Un robot me ha visitado ¿qué tengo que hacer? ¿Cómo evito que un robot indexe mi sitio? Pero si hago una relación de los archivos que no quiero que un robot añada a su índice, le estoy diciendo al resto de la gente qué documentos privados tengo. Los hago invisibles a los robots de búsqueda pero accesibles tecleando la dirección. La manera óptima de organizar un sitio es incluir en un directorio secundario todos los documentos y archivos que no queremos que indexen los buscadores, prohibir la entrada de los robots en ese directorio y configurar el servidor con unas buenas medidas de seguridad en el caso de tener documentación sensible. El robots.txt no es una medida de seguridad que garantiza la privacidad de los documentos, para eso existen otros métodos, el robots.txt es el resultado de un consenso para evitar que los robots añadan automáticamente a sus índices esos documentos. Mi proveedor no me da esa posibilidad ¿Existe otra manera para indicar a los robots qué zonas pueden indexar de mi sitio? ¿Por qué encuentro llamadas /robots.txt en mis ficheros? Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Compatibilidad de tu web con distintos navegadores Qué es la compatibilidad web? El problema radical en que no todos los navegadores interpretan en código HTML y CSS de la misma manera, entre ellos existen pequeñas variaciones que son las que hacen que el resultado no sea el mismo de unos a otros. Algunas de esas diferencias son tan importantes que pueden hacer que partes de tu web no funcionen o no se vean, y como el propósito de hacer una web es que la vea el mayor número de personas (y que éstas la vean correctamente), nos interesa que la web funcione en el mayor número de navegadores posibles. Por tanto, a la hora de hacer una página web no es suficiente con preocuparse por centrarnos en la audiencia adecuada, registrar un nombre de dominio rompedor o tener un diseño agradable al usuario. Todo esto puede verse ensombrecido si un usuario no ve la página correctamente al entrar con un navegador que no has tenido en cuenta al crearla. Para que veas un ejemplo leve de lo que hablamos, aquí puedes apreciar como se ve una página web en diferentes navegadores. Por supuesto es ficticia y el diseño está hecho descuidado a propósito: Como hemos dicho, hay casos de incompatibilidad más graves en los que el diseño se desajusta, no cabe completo en pantalla, scripts o menús que se comportan de manera diferente de un navegador a otro… en fin, un desastre, sobre todo si tu web es un negocio en línea o una página de empresa que requieren cuidar el aspecto al máximo para atraer al cliente. Mejorar la compatibilidad con navegadores Para validar tu CSS lo mejor es usar las herramientas disponibles, ya que si te propones hacerlo manualmente la tarea será difícil y larga. Además, es muy sencillo que se te pasen errores, mientras que usando herramientas online no ocurrirá. El validador de CSS del W3C es la mejor opción para ello, ya que esta entidad es la que se encarga de crear los estándares de la web. Resetear los estilos CSS Por eso, resetear tu hoja de estilos es una de las mejores medidas que podemos adoptar para prevenir el problema de la incompatibilidad entre navegadores, ya que por defecto, todos los elementos HTML tienen unos atributos CSS predeterminados. Así, los márgenes, espacios y tamaños de fuente de títulos (entre otros) pueden tener diferentes propiedades por defecto de un navegador a otro y provocar que se vean diferentes por mucho formato que le demos nosotros. Al resetear el CSS digamos que ponemos a cero esos valores por defecto y podemos empezar desde el principio a dar el formato que nosotros queramos, controlando el aspecto de cada elemento mucho mejor. Para resetear el CSS se escribe un código CSS al principio de tu hoja de estilos, y después todo lo que tu vayas creando. El código de Eric Meyer es una de las formas más conocidas que tenemos de resetear el CSS de nuestra web, muy efectivo:
Quote html, body, div, span, applet, object, iframe, h1, h2, h3, h4, h5, h6, p, blockquote, pre, a, abbr, acronym, address, big, cite, code, del, dfn, em, font, img, ins, kbd, q, s, samp, small, strike, strong, sub, sup, tt, var, dl, dt, dd, ol, ul, li, fieldset, form, label, legend, table, caption, tbody, tfoot, thead, tr, th, td { margin: 0; padding: 0; border: 0; outline: 0; font-weight: inherit; font-style: inherit; font-size: 100%; font-family: inherit; vertical-align: baseline; } /* remember to define focus styles! */ :focus { outline: 0; } body { line-height: 1; color: black; background: white; } ol, ul { list-style: none; } /* tables still need 'cellspacing="0"' in the markup */ table { border-collapse: separate; border-spacing: 0; } caption, th, td { text-align: left; font-weight: normal; } blockquote:before, blockquote:after, q:before, q:after { content: ""; } blockquote, q { quotes: "" ""; } Por otro lado, una forma más sencilla, aunque no tan completa, de anular los valores por defecto que más problemas suelen dar (margin y padding) es poner el siguiente código al principio de tu hoja de estilos y luego las reglas que vayas creando:
Quote * {margin:0; padding:0} Lo que hace este código es dar un margin y padding de 0 a todas las propiedades CSS. Evidentemente no es tan completo como el anterior código, pero si no quieres complicarte mucho la vida o necesitas ahorrar espacio reduciendo la hoja de estilos, este código también quita muchos problemas. Diseñar para Firefox, no para Explorer Diseñar optimizando para Firefox hace de nuestro código un código más limpio, más estándar, y por tanto más universal. Una vez funcione en Firefox, puedes empezar a pensar en que tu sitio se vea bien en Explorer. Si lo haces al revés, cuando consigas que se vea bien en Explorer tendrás que ir arreglando el código para que se vea bien uno por uno en el resto de navegadores, mucho más trabajo ¿no?. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Como añadir imágenes a una página web
Para añadir imágenes a una página web hay que escribir el siguiente código HTML:
Quote <img src="archivo.jpg"> src indica la ruta del archivo. Si el archivo de imagen se encuentra en la misma carpeta que la página web se escribiría como en el ejemplo, pero si se encuentra en una carpeta distinta la ruta podría ser así:
Quote src="carpeta/archivo.jpg". También se puede llamar a una imagen con la dirección completa:
Quote src="http://www.web.com/images/archivo.gif". Ahora bien, es conveniente añadir otros atributos al código de la imagen:
Quote <img src="archivo.jpg" width="300" height="150"> En este caso la imagen tendría un ancho de 300 píxeles y un alto de 150 píxeles.
Quote <a href="carpeta/web.html"><img src="archivo.gif"></a> Donde href establece la ruta de la página a la que dirigirá la imagen. Otro ejemplo:
Quote <a href="http://www.ucoz.es/"> <img src="carpeta/archivo.gif"></a> • Atributo alt: este atributo especifica un texto alternativo que se muestra en lugar de la imagen cuando ésta no existe o el navegador no es capaz de cargarla. En estos casos, el texto alternativo es la única forma que tienen los visitantes de conocer el contenido de la imagen. El atributo alt se expresa así:
Quote <img src="nombrearchivo.jpg" alt="texto alternativo a mi gusto"> • Establecer el borde: toda imagen en la web puede tener un borde de un grosor determinado. Según tus preferencias podrás determinar si la imagen tiene o no borde, y en caso de tenerlo su grosor. Ejemplos:
Quote <img src="nombrearchivo.jpg" border="0"> Imagen con borde de 3 píxeles:
Quote <img src="nombrearchivo.jpg" border="3"> Atributos completos del código de la imagen
Quote <a href="paginaweb.html"> <img src="archivo.gif" width="300" height="150" border="5" alt="texto alternativo de la imagen"></a> Algunos errores comunes en la utilización de imágenes en la web Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
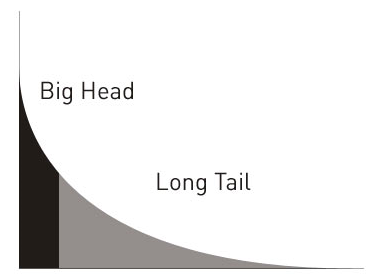
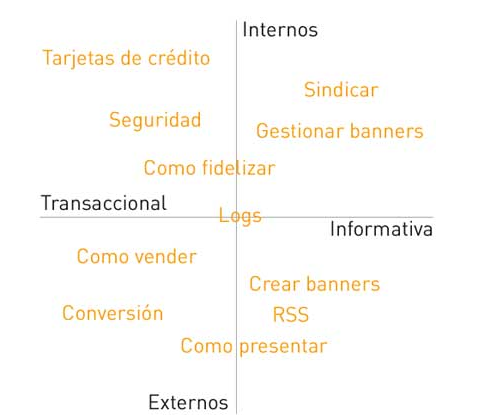
Arquitectura de la información Desarrollo del proceso inicial para diseñar la arquitectura de la información. Entender las necesidades del usuario y los objetivos del sitio web. Arquitectura de la información Arquitectura de la información es la tarea de organizar la información dentro de un proyecto interactivo. Todo empezó con Jesse James y el diagrama de la experiencia del usuario. El esquema resume los pasos a seguir para realizar un buen diseño centrado en los usuarios. Estos pasos son los elementales y son los que nos deben marcar la pauta en nuestro desarrollo. En este artículo vamos a desarrollar el primer paso. Entender las necesidades del usuario y los objetivos del sitio web. Las necesidades del usuario ¿A quién nos dirigimos realmente? ¿Qué quieren? ¿Qué buscan? El cliente de nuestra empresa es el mismo que el cliente de nuestra web Un aspecto a tener muy claro es que por estar en internet no tenemos que cambiar nuestros objetivos, forma de comunicar, vender. Que nuestra empresa esté en internet sólo quiere decir que el canal es internet. Nuestro público objetivo, sus necesidades no tienen porque ser nuevas o diferentes al canal offline. Al principio de Internet se podía decir que el usuario de la web eran los "usuarios avanzados" y que por tanto el contenido a poner en Internet debía apelar a este usuario. Ahora los usuarios de Internet son tantos que se puede decir que representan a la sociedad "offline" de forma fiel y por tanto no debemos pensar que la audiencia en Internet va a ser muy diferente a la audiencia offline. Mantener el tono de voz Dar el paso a Internet no quiere decir que la empresa tenga que transformar su presencia, tono de voz, etc... Al principio de Internet muchas empresas cambiaban su nombre, forma de comunicar, etc... para posicionarse en internet sin debilitar su presencia offline. Los casos más notorios fueron los de los bancos que sacaron marcas nuevas para tener una presencia en internet alejada de la marca offline. Actualmente la presencia web se ha normalizado y ya todas las marcas mantienen el tono de voz e identidad offline y online. Identificando las necesidades del usuario Es muy importante llegar a identificar los tipos de usuario objetivo de la web y las necesidades reales de estos. Aun así, una vez tengamos definido el tipo de usuario y sus necesidades deberemos seguir puliendo los detalles hasta encontrar los aspectos que harán al usuario actuar, interesarse, fidelizarse, opinar, etc... Supongamos los siguientes escenarios. El País. Público objetivo. Entre 15 y 85 años, todos los niveles económicos. Información general. Alzado.org. Público objetivo. Entre 20 y 40. Todos los niveles económicos. Información sobre desarrollo web. Big head, long tail La perfilación de usuarios que hemos puesto como ejemplo son las del "Big Head". Esta perfilación es la útil para desarrollar campañas de comunicación o venta "al viejo estilo". Es decir, si uno tiene que lanzar un spot en televisión que se supone va a ser expuesto a millones de televidentes, uno debe apuntar al "Big Head". ¿Cúal es el problema del "Big Head"? Que el Big Head como tal va desapareciendo. Incluso en los medios tradicionales (televisión, radio, prensa) las audiencias se van especializando y el "big head" desaparece. Ahora aparece el "Long Tail". El long tail es la gran masa de usuarios dispersos que es algo más complejo encasillar. El "long tail" aparece por todas partes y su presencia es cada vez más clara gracias a las nuevas herramientas de medición que nos permiten conocer mejor a la audiencia. La concentración de la audiencia es cada vez más baja. Cada vez es mas barato lanzar canales de comunicación haciendo que la audiencia se fraccione en millones de nichos. Para poder aprovechar el Long Tail son necesarias nuevas herramientas, nuevos sistemas y sobre todo nuevas formas de pensar. Las empresas que han sabido desarrollar sistemas de comunicación, venta, gestión más automáticos, pueden aprovechar el "Long Tail" de usuarios ya que es rentable y sencillo diseñar productos para nichos de mercado en lugar de desarrollar únicamente productos para el "Big Head". En el caso del País, supongamos las siguientes necesidades del usuario. No es un desglose especialmente brillante, pero podría ser un punto de partida... y entonces uno se pregunta... ¿por qué tienen esta barra de navegación como elemento principal? Miremos el caso de Alzado.org En alzado tenemos un perfil de usuario antes definido. Pero podríamos matizar algo más. Pero podríamos seguir matizando en detalles para poder afinar más y es aquí cuando entran los "cuadros o mapas de usuarios". Esta técnica es bastante sencilla y nos permitirá desarrollar conceptos sobre usuarios y contenidos a desarrollar. La técnica se basa en crear un eje de coordenadas y plantear valores sobre el mismo y en torno a esos valores posicionar contenidos. Por ejemplo: En este cuadro pretendemos ilustrar el caso de poner como objetivo satisfacer las necesidades de "gestores de proyectos". Hemos creado la división entre internos (trabajan dentro de la compañía) y externos (trabajan como proveedores de un servicio tipo consultoria) y entre webs transaccionales y de información. Quizás los conceptos puestos no sean del todo acertados pero pretenden demostrar como podemos ir pensando en "temas" de interés para esta audiencia y en desarrollar secciones, apartados, etc... que sirvan para satisfacer a este sector que pueda resultar estratégico. Este ejercicio nos debería ayudar a perfil tipos de usuarios y necesidades. La idea de este ejercicio es hacer tantos como escenarios posibles. En el caso de Alzado podríamos tener los siguientes casos. • Programadores Y a todos estos perfiles les podríamos cruzar con los siguientes valores. • Ingresos Con este esquema obtenemos cientos de cuadros que nos darán una idea concreta de que contenidos pueden adecuarse a cada grupo y ante esa "foto" poder decidir que priorizamos, que podemos atender sin problemas, que puede ser mas rentable... Esta idea es importante ya que la web se desarrolla más en torno al "Long Tail" que en torno al "Big Head". La web es la herramienta perfecta para captar miles de micro nichos que las ediciones offline no pueden captar (por distribución, precio, etc...). Es importante desarrollar cuadros de necesidades de usuarios por cientos y luego con las herramientas adecuadas ser capaces de empaquetar el contenido en un formato que satisfaga a estas audiencias. Los objetivos del sitio web Sobre este punto debemos desarrollar algunas ideas. La comunicación, el lenguaje, los menús, suelen responder principalmente al orden y estructura interna de la propia empresa. Podríamos decir que Google es un ejemplo de este tipo de organización. Google ha ido incorporando aplicaciones a su sitio web sin ningún tipo de orden con el único criterio de "lo hemos lanzado". Algunas aplicaciones están accesibles desde la portada, otras desde el "more" y dentro del more la división responde a un criterio interno de Google de "Services" y "Tools". Por lo general es muy complicado reorganizar la estructura de una empresa para acomodar las necesidades del usuario. Este problema viene del origen propio de las empresas. Hay muy pocas empresas que se dirigen a consumidores finales. La mayoría de las empresas se dedican a B2B y una gran mayoría de todas las empresas en general están dirigidas por personas que están centradas en aspectos de producción, fabricación o distribución y no en el marketing o comunicación. La arquitectura de la información para este tipo de empresas suele ser un proceso complejo de digerir. Su lenguaje se basa en aspectos internos, productos, sistemas, fabricación. Este lenguaje interno de la empresa asumirse inicialmente como válido intentando darle su lugar dentro de una arquitectura con un lenguaje algo más claro. Un método de trabajo Con las empresas el método de trabajo suele pasar por conocer su lenguaje y entorno. Como hemos dicho antes, la mayoría de las empresas se dirigen a otras empresas y por tanto el lenguaje del sector suele ser el apropiado. Un lenguaje técnico, profesional, directo es el adecuado y por tanto debemos escuchar y aprender del cliente lo que tenga que decirnos sobre como comunicar su producto. Este lenguaje se ha de contrastar con el del sector y sobre todo con los líderes del mismo. Por lo general existen muchas dudas a la hora de posicionar productos o servicios en la web. ¿Se ha de comunicar el servicio, los productos resultantes, las herramientas (en caso de ser conocidas)...? Aquí es donde el arquitecto de la información entra en juego y ha de resolver el problema proponiendo soluciones que ayuden a expresar de la manera más acertada posible la información del cliente. Podríamos decir que la solución suele pasar por emplear todas las posibilidades de comunicación priorizando aquellas que puedan ser más relevantes. Ejemplo: Un arquitecto de la información debería conocer las necesidades de los usuarios (como hemos visto antes) y junto a eso ordenar las necesidades del cliente. Por las necesidades del usuario podrían aparecer términos como "folleto", "diseño", "logotipo"... y cosas así. Con todos estos términos el Arquitecto de la información debería plantear el siguiente esquema. Para convertir esto en una navegación, uno tendría que ver webs de la competencia y entonces podría proponer algo del siguiente estilo... Con esta navegación ya podemos empezar a pintar el site y las páginas de contenido que son los siguientes pasos en el esquema de Jesse James. Resumen de los pasos iniciales de la Arquitectura de la Información 1. Conocer las necesidades del usuario. 2. Conocer las necesidades de la empresa. 3. Resolver los problemas dentro de este contexto y no inventando nuevos productos, términos que sean ajenos a la empresa. Creo que es muy importante que la labor del Arquitecto de la Información esté dentro del contexto real de la empresa. Si uno sabe como resolver la arquitectura dentro de la terminología propia de la empresa el producto final es más creíble y por otro lado es más cercano a la propia empresa y por tanto será mejor desarrollado en el futuro. Si el producto final es ajeno a la jerga propia de la empresa, será complejo de mantener, actualizar, mantener. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
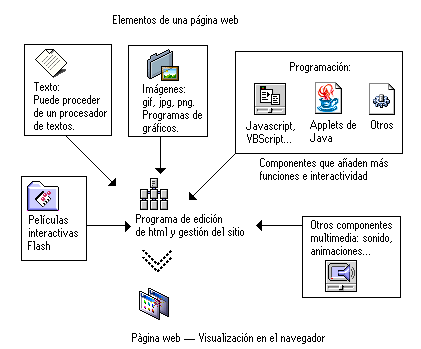
Anatomía de una Página Web La composición de una página web como ésta puede considerarse desde el punto de vista de su diseño o atendiendo a las partes y tipos de fichero que la componen. Empezaremos por este segundo enfoque. Es preciso entender bien de qué está formada una página para poder aprender con éxito como crearlas y modificarlas. Una página web es superficialmente parecida a cualquier otro documento: un texto, unas imágenes, todo compuesto de una determinada manera. Una página web es un tipo de fichero que tiene poco de particular: se trata simplemente de un fichero de texto, con una extensión .htm o .html (de hypertext markup language - lenguaje de hipertexto.) Este fichero contiene el texto más una serie de códigos que permiten dar formato a la página en el navegador: por ejemplo, distribuir en columnas, poner letras en negrita, asignar colores, rodear una imagen con texto... El programa navegador (normalmente Internet Explorer o Navigator) interpreta los códigos del html para mostrar en pantalla la información contenida y del modo que se ha especificado aquellos códigos. Para comprobar todo esto, lo más fácil es abrir el Bloc de Notas de Windows o, si habéis hecho caso de nuestras recomendaciones, el NoteTab, y con él abrir un documento web cualquiera del disco. Si aún no domináis el tema, y no sabéis dónde pueda haber alguno, guardad esta misma página, o bien buscad con el explorador de Windows ficheros con la extensión htm (buscar: *.htm), puesto que muchos programas incluyen su ayuda en forma de hipertexto web. ¿Qué sucede con las imágenes y otros añadidos que la página web, aparentemente, "contiene"? Estos son ficheros adicionales que NO están dentro del fichero htm; están enlazados con un código que indica al navegador qué imagen debe mostrarse, dónde está, sus dimensiones, si es o no un enlace... Así que la página web, vista con un editor de texto, contiene una mezcla de texto normal y una serie de códigos. Estos códigos del lenguaje html son siempre del estilo <head> y </head>, por ejemplo. Siempre van entre llaves, y cada código tiene una forma inicial y otra de cierre que indican el intervalo de texto o imágenes que reciben el formato correspondiente. Por ejemplo, un párrafo se encierra entre las etiquetas o tags <p> y </p>. Al principio todo esto puede parecer lioso, ¡y lo es! Pero la idea se puede captar en cinco minutos, y a los cinco minutos siguientes, tener una página lista, sólo con el bloc de notas y una chuleta o cheat sheet de los códigos al lado. Todo el que se haya atrevido a crear una página web antes de 1995 habrá aprendido a escribir en html, casi sin darse cuenta... Pero, ¿es necesario hoy en día dominar, o al menos tener una idea de cómo está estructurado el lenguaje html? Difícil cuestión: Sí y no. Francamente, es muy conveniente tener una idea básica. Igual que cuando conducimos un coche, sin necesidad de ser unos diplomados en mecánica, al menos sabemos qué son los componentes principales del coche y para qué sirven... Así, aunque utilicemos un editor visual de páginas web, conocemos la terminología del código que generan en la sombra, y podemos hacer si es preciso algún retoque manualmente. Para tener una idea, podemos consultar uno de los muchos libros disponibles, alguna de las muchas webs que tratan el tema. Un repaso a los principales componentes de la página web típica (ver ilustración en la parte superior de esta página): 1. Texto. El texto editable se muestra en pantalla con alguna de las fuentes que el usuario tiene instaladas (a veces se utiliza una tecnología de fuentes incrustadas , con lo que vemos en el monitor una fuente que realmente no poseemos, pero es poco frecuente.) El texto editable puede marcarse con el ratón o el teclado y copiarse a otra aplicación, como el bloc de notas (muchos de los elementos textuales de las páginas, en especial los títulos, botones de navegación, etc. son realmente gráficos, y su texto no es editable.) Existen otros componentes que, más que formar parte de las páginas web, las acompañan y suelen guardarse al disco duro para después verlos o ejecutarlos: Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
ENLACES RECÍPROCOS
Uno de los temas más comentados en cualquier foro en los últimos meses es el papel que juegan los enlaces recíprocos en Google. Un tema de consideración ya que el carácter recíproco de los enlaces es algo muy común en muchos intercambios de enlaces. Desde la conocida actualización Florida, que Google llevo a cabo hace un año, han surgido diversos rumores sobre los intercambios de enlaces y las posibilidades de que los enlaces recíprocos estén devaluados o hayan perdido todo su valor. Los enlaces recíprocos no están devaluados, ni penalizados, ni han perdido valor. Los intercambios de enlaces (recíprocos o no) siguen jugando un papel fundamental en la metodología SEO. ¿Páginas o Webs? Hay un caso en el que Google favorece a las páginas del mismo dominio. Cuando hay dos páginas de un misma web dentro de la página de resultados de búsqueda, Google agrupa la que ocupa el peor lugar justo después de la primera. Me explico: si tenemos configurado Google para mostrar 10 resultados por página, y yo tengo una página en la segunda posición de una búsqueda, si otra página de ese dominio alcanza la décima posición, automáticamente pasa al tercer puesto, es agrupada de forma consecutiva con la otra página del dominio. Si tenemos Google configurado para mostrar 100 resultados por página y tenemos la quinta posición y la nonagésimo novena, ésta última saldrá listada en la sexta posición. Podemos establecer como regla general: Cuando en la misma página de resultados de Google salen listadas dos páginas del mismo dominio en posiciones no consecutivas, Google agrupa las dos páginas, de forma que la que ocupa el peor puesto de las dos, es listada a continuación de la que ocupa el mejor puesto de ambas. ¿Qué es un Enlace Recíproco? A veces se habla de enlaces recíprocos cuando hay enlaces bidireccionales entre dos dominios, pero no entre las mismas páginas. Explicado: Tenemos un dominio "D1" y un dominio "D2. "D1" tiene una página "A" que apunta a una página "C" del dominio "D2". "D2" tiene una página "B" que enlaza a la página "A" de "D1". Sean "D1" y "D2" dominios difentes, "A" una página del dominio "D1", "B" y "C" páginas diferentes del dominio "D2", y "z -> x" representa un enlace de "z" a "x". Tenemos: D1.A -> D2.C y D2.B -> D1.A ¿Podemos considerarlos enlaces recíprocos? Si bien son enlaces entre dominios, no deben considerarse enlaces recíprocos, ya que hay infinitas posibilidades de que se dé este caso, y es prácticamente imposible de controlar. No representa ningún riesgo este tipo de intercambios. Pensemos en el mundo de los blogs, prácticamente todos los enlaces serían recíprocos, la mayoría hemos enlazado a casi todos los blogs que nos han enlazado en algún que otro post. ¿Qué se ha devaluado? Éste fue uno de los motivos que impulsó la creencia de que los enlaces recíprocos estaban devaluados. Era fácil comprobar que esos enlaces no funcionaban para mejorar posiciones como lo hacían antes, pero lo devaluado no era el enlace en sí por el hecho de ser recíproco, era la procedencia de enlaces masivos desde la misma IP. Recíprocos vs. No Recíprocos Los enlaces entre páginas relacionados son la mejor forma de subir posiciones en Google, ya sean recíprocos o no. Simplemente porque el que sean recíprocos no perjudica en nada. Se pueden observar grandes beneficios con intercambios de enlaces entre páginas que compiten por la misma búsqueda. Estos enlaces son de gran valor para el usuario, y Google sabe valorarlos en su justa medida. Si lo que se valora son los enlaces naturales, lo adecuado es hacer intercambios de enlaces naturales. Tal vez no enlacemos a otra web por el simple hecho de que sea de la competencia, pero los usuarios, y por tanto los buscadores, saben valorar ese tipo de enlaces positivamente. Porque están relacionados, porque ofrecen una continuación a ese página, porque es una aportación de contenido útil, y si el enlace se hace recíproco... ¿Qué importa? Peligros Las penalizaciones a grandes anillos de enlaces en los que participan un número muy elevado de páginas... ¿tienen algo que ver con los enlaces recíprocos? No. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Optimización de la página web para todas las resoluciones Actualmente casi todas las páginas están optimizadas únicamente para una resolución de 800 x 600 píxeles, y aunque la mayoría de equipos actualmente están configurados a dicha resolución, los monitores más antiguos no soportan más de 640 x 480 píxeles, y por el contrario, los equipos de última generación suelen tener configurado el monitor a 1024 x 768 píxeles, y pueden soportar hasta 1280 x 1024. La optimización de una página únicamente a una resolución de 800 x 600 píxeles, puede llegar incluso a ser algo más que molesto para monitores de 640 x 480 píxeles, e incluso llegar a imposibilitar la navegación cuando se desactiva la opción de scroll de página en webs desarrolladas con frames. Para solucionar este problema existe una posibilidad y aunque es un poco laboriosa, merece la pena ya que se consigue tener un sitio web optimizado para todas las resoluciones que se deseen. Para ello es muy importante una buena organización desde el principio. La estructura de las carpetas si es la adecuada como se explica a continuación, permitirá ahorrar mucho trabajo, ya que evitará tener que renombrar archivos, editar vínculos y repetir imágenes que aumentan innecesariamente el tamaño del sitio con la consiguiente pérdida de tiempo al subirlos. Para ello se recomiendan los pasos siguientes: 1. Crear una carpeta principal donde estará alojado el sitio web Ej. "miweb"
Quote <script language="JavaScript1.2"> /* Diferentes versiones según la resolución (Por Miguel Cruz, http://www.signo-net.com ) */ //para resolucion 800x600 if (screen.width==800||screen.height==600) window.location.replace("es800600/index.html") // para resolucion 640x480 //para resolucion 1024x768 //para otras resoluciones 9. Ahora automáticamente el archivo principal index.html detectará la configuración del monitor del cliente y se cargará la versión correspondiente en función de la resolución detectada. NOTAS: Asimismo hay servidores donde los cgis no funcionan fueran de la carpeta cgi-bin, con lo cual se complicará un poco el trabajo teniendo que modificar enlaces y renombrar archivos que era lo que se pretendía evitar. Se puede añadir una cuarta carpeta: "otros" para añadir una cuarta versión de resolución que se cargará cuando no se cumple ninguna de las tres resoluciones anteriores, debido a que el monitor tiene una resolución mayor. Si no se va a realizar una cuarta versión, que tampoco recomiendo, ya que con tres versiones está bastante aceptable, dejar la versión para la resolución mayor que tengamos, ya que si no cumple ninguna de esas tres resoluciones será porque, lo más probable es que tenga configurado el monitor para una resolución mayor. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Cinco pasos hacia páginas más profesionales con Dreamweaver Dicen que un mal artesano siempre le echa la culpa a sus herramientas. Y tienen razón. No importa lo buena que sea la herramienta, es la destreza de la persona que la utiliza lo que produce buenos resultados. Este artículo esboza los cinco pasos necesarios para obtener resultados más profesionales con Dreamweaver MX. Paso 1: Exporte JavaScript y CSS a archivos externos Aunque crea que mantener todo el código en una página base es más conveniente para la edición, es un gran desperdicio de ancho de banda. Si retira el código JavaScript y CSS de la sección <head> de cada página y lo pone en archivos centrales, logrará dos cosas útiles: • Centralizar el código. Si tiene que hacer cambios al código, sólo tiene que hacerlo una vez en lugar de una vez para cada página que lo utiliza. Para lograr esta tarea, primero busque las funciones de JavaScript en la sección <head> de su documento. El siguiente es un ejemplo típico:
Quote <script language="JavaScript" type="text/JavaScript"> <!-- function MM_openBrWindow(theURL,winName,features) { //v2.0 window.open(theURL,winName,features); } //--> </script> Copie cualquier función en un nuevo archivo de texto y guárdelo con el nombre common.js, por ejemplo. Cree vínculos al mismo en la sección <head> de cada página de su sitio (o póngalo en su plantilla), como sigue:
Quote <script language="JavaScript" type="text/JavaScript" src="/common.js"> </script> Busque el código CSS en la sección <head> de sus páginas, cópielo al nuevo archivo de texto y guárdelo con el nombre mystyles.css, por ejemplo. Lo siguiente es lo que hay que buscar en la sección <head>:
Quote <style type="text/css"> <!-- h1 { font-family: Arial, Helvetica, sans-serif; font-size: 14px; font-weight: bold; color : #000000; } --> </style> Vincule el archivo CSS a la página web mediante un vínculo al archivo CSS en la sección <head> de la página:
Quote <link href="/mystyles.css" rel="stylesheet" type="text/css" /> Paso 2: Exporte su sitio sin marcación de plantilla Dreamweaver puede retirar estos comentarios y producir una nueva versión limpia del sitio. (Pero no pierda los comentarios de la versión en la que está trabajando, de lo contrario la plantilla podría romperse.) Para hacer esto, elija Modificar > Plantillas> Exportar sin formato desde su sitio. Navegue a una nueva ubicación para su sitio ya limpio y haga clic en Aceptar. Si hace codificación manual, hay unas cuantas cosas que debería saber acerca de XHTML antes de convertir los archivos. Por ejemplo, la norma XHTML prefiere atributos que no estén vacíos y etiquetas correctamente emparejadas y anidadas. Si trabaja en un entorno visual como la mayoría de usuarios, es fácil convertir sus páginas en maravillas de XHTML: Paso 4: Ordene el código con el comando Aplicar formato de origen En las páginas largas y complejas, el usuario no tarda en desorientarse usando la vista de código. Cualquier programador profesional le puede decir lo importante que es tener código bien presentado y con sangrías cuidadosamente insertadas. Los siguientes son algunos de los beneficios de tener un código con un buen formato: Paso 5: Valide la página para buscar errores básicos Los usuarios de Dreamweaver MX tienen dos maneras de validar su código. La primera manera es en Dreamweaver. Asegúrese de que ha guardado la página en la que está trabajando. Luego seleccione Archivo > Comprobar página. Seleccione ya sea Validar formato si la página es HTML o Validar como XML si la página es XHTML. El panel Resultados aparecerá con una lista de los problemas que ha encontrado. La segunda manera de validar la página es utilizar la herramienta de validación en línea del World Wide Web Consortium (W3C). Puede validar todos los tipos de HTML y XHTML, así como archivos CSS. Los validadores se encuentran en el sitio web del W3C: Es realmente asombroso ver la diferencia en la página después de corregir errores menores. Por ejemplo, una etiqueta mal anidada puede impedir que aparezca una página en un navegador pero permitir que aparezca sin problemas en otro. Sólo esto es una gran razón para dejar que los validadores de código hagan el trabajo difícil por usted. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Cómo diseñar una portada que cautive a sus visitantes Por poco que os mováis en Internet en los sitios de marketing y comercio, veréis que los aspectos de promoción y publicidad de webs son profundamente tratados en todas partes. Sin embargo, no hay mucho sobre un tema que es clave para el éxito de todo sitio: las portadas. Aquí le contamos que debe tener en cuenta para diseñar una “home page” cautivadora. Efectivamente, no sirve de nada invertir en promoción para atraer a muchos internautas a nuestras páginas si, en el momento en que se acerquen, pasan breves instantes ojeando la portada de nuestro sitio web y, seguidamente, se van hacia otros lugares. ¿Cómo los captamos? ¿Cómo los retenemos? ¿Cómo conseguimos que se queden el tiempo suficiente para conocer nuestra oferta y permitirnos iniciar con ellos una relación con visos de continuidad? Antes, intentemos definir cuáles son los objetivos a cubrir por nuestro sitio web. 1. "Enganchar" los contactos que se acercan a visitarnos por primera vez Estos deberían ser los objetivos prioritarios de nuestro sitio. Si los alcanzamos, ya dispondremos de la base para la continuación del proceso de la venta. Podremos entonces establecer relaciones permanentes con nuestros clientes, ganarnos su confianza, generar ventas y ventas repetitivas. Pero ¿se ha planteado cómo alcanzar estos objetivos? Pero veamos ahora, qué va a necesitar nuestra portada para cumplir los objetivos: diseñar la portada pensando en el cliente. ¿Qué le gustaría encontrar a nuestro cliente? ¿Cómo podemos facilitarle la vida? ¿Cómo podemos servirle mejor? El sitio web no es para nosotros ni para nuestra empresa ni para nuestro consejero delegado. El sitio web es para nuestros clientes. Y lo mejor es pensar en lo que hacemos cada uno de nosotros al entrar a un sitio web que visitamos por primera vez. Lo que yo hago es sobrevolar con la vista el conjunto de la página a la caza de esa palabra o ese detalle que capta mi atención. Desde luego, en el primer vistazo no suelo dedicarme a leer grandes párrafos. Mi interés ha de ser captado de alguna otra forma, de una forma rápida, al vuelo. El visitante debe encontrar en la portada los siguientes elementos: 1) Debe poder identificar qué es lo que proporciona el sitio web a sus visitantes. Es decir, "para qué le sirve a él ese sitio web". Otras opciones son el suministro de un informe concreto, el rellenar una encuesta, a cambio de lo cual, participarán en un sorteo o recibirán un determinado servicio durante 3 meses (de paso, les hacemos conocer el servicio y, si les gusta, ya se suscribirán al cabo de los tres meses) 5) Por último, la cantidad de información debe ser la justa. Ni poca, ni mucha. Ni tan poca que resulte insustancial, los clientes no harán el esfuerzo de entrar a otra página sin saber lo que van a encontrar. Ni tanta que la página resulte sobrecargada con múltiples textos de letra menuda. Esa sobrecarga de información tiene como principal efecto el enmascarar la información importante, ésa que es capaz de captar la atención del cliente. ¡Bien, pero basta ya de generalidades! ¡Vayamos al grano! La página de portada, como hemos comentado, debe ser útil a visitantes noveles y repetidores. A los primeros, debe captarlos. A los segundos, llevarles lo más rápidamente posible a la sección a la que se dirigen. Pongamos, pues, dos formas distintas de salir de ella para penetrar en el sitio web por dos vías distintas. La entrada de los repetidores...... .....y la de los nuevos contactos ¿Queréis un ejemplo? Imaginemos una tienda virtual de ciclismo. Podríamos identificar varios tipos de clientes potenciales: el profesional, el aficionado y el cicloturista, que sólo quiere una bicicleta de montaña para salir de vez en cuando con sus amigos. Lo que yo propongo es presentar una llamada explícita a cada uno de ellos en nuestra portada. Para el tercer cliente pondríamos, por ejemplo, "¿Te gusta el cicloturismo? Haz click aquí y pasa a nuestro ciclomundo (o bien "encuentra todo lo que necesitas" o bien "Tenemos unas páginas que te encantarán")". Difícilmente, un visitante que responda a ese perfil dejará de entrar. Bien, ya tenemos nuestra portada con la doble vía de salida. También disponemos de todas las páginas de contenidos (artículos, catálogo, página de pedidos, enlaces, foros, etc.) Bien, pero, como consecuencia de la portada que hemos creado, nos falta algo. Debemos crear un nuevo nivel de páginas. En efecto, volviendo a nuestro ejemplo, una vez que el clicloturista ha pulsado el botón que le pedíamos debe entrar a una página íntegramente dedicada a él, a los cicloturistas. En esa página debemos presentarle todas las opciones, productos y servicios que va a encontrar para él a continuación. Por ejemplo, un sitio como ese debería ofrecer el catálogo de bicicletas y accesorios, pero también información de rutas cicloturistas, un foro de contactos para intercambio de materiales usados, un tablero de anuncios para la organización de excursiones conjuntas, etc. Por lo tanto, en esa página, que llamo de orientación, se trata de contarle a nuestro nuevo visitante cicloturista todas las secciones de que dispone en nuestro sitio y qué le ofrece cada una de ellas. Desde esa página, nuestro cicloturista podrá acceder directamente a cada una de las secciones que le ofrecemos. Cuando ese mismo cicloturista regrese a visitarnos, probablemente ya accederá directamente a la sección que busque desde el menú de la portada. Claro, ahora ya es un visitante repetitivo. La aplicación de este modelo os puede servir, no sólo para mejorar sustancialmente los resultados de vuestro sitio web, sino que tendrá el efecto de cambiar la forma que teníais de concebirlo. El sólo hecho de intentar aplicar este modelo, os obligará a pensar en los tipos de clientes que tenéis, o queréis tener, en los contenidos que podéis ofrecer a cada uno de ellos y, en definitiva, os ayudará a replantear desde una óptica más adecuada al medio Internet, toda vuestra presencia en la red. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Algunos errores del diseño web Pff… Ahora si que he estado desaparecido mi gente. Me disculpo, pero he tenido un periodo de mucho estrés, sustos, trabajo, gastos… en fin. Me ha sido imposible postearles algo por aquí. Pero heme aquí, haciendo un tiempesito para revivir el blog un poco. Cansado de ver muchas prácticas poco aconsejables (y que, honestamente, hasta hace poco yo también cometía) y como la excusa perfecta para darles a conocer que sigo vivito y coleando (aunque aún sumamente ocupado), he decidido escribir sobre los 8 grandes errores del diseño web actual. Estas son prácticas que el mundo de la web 2.0, los estándares web y, por sobre todo, la idea de separar la presentación del contenido nos han metido en la cabeza y la mayoría de las veces las hemos seguido sin ponernos a pensar un poquito en las consecuencias. Primero que nada, vamos a definir diseño web. Diseño web abarca ya no solo lo visual; es toda una ciencia que involucra accesibilidad, apariencia, presentación, contenido, contexto, mensaje e interactividad (si no es que más). Un diseñador web debe ser capaz de, a partir de una idea, generar una solución virtual. Ojo con la palabra: solución. Y para generar una solución, necesitamos tener un problema para empezar. En el caso generalizado de la web, el problema a resolver es el manejar información. Ya sea presentando o editando, visual o auditiva, útil o no tanto; la web es información y nada más. Cómo la manejamos depende de las necesidades que tengamos, y es aquí donde cometemos los 8 grandes errores del diseño web: ¡Las imágenes también son contenido! No me malentiendan. La técnica (o más mejor bien dicho, las técnicas) en si es muy buena y cumple su cometido, además de ser un excelente impulsor visual para nuestras páginas. Los dos problemas que nos encontramos vienen de nuestro lado, de la práctica y no la teoría. Mal uso de la técnica ¿Y por qué digo que es un mal uso? Pues porque la técnica de reemplazo de imagenes es para un tipo de media, y uno solo: screen (que significa pantalla). Una impresora no debería tener el image replacement. ¿Por qué? Porque la impresora no va a imprimir la imagen de fondo ni el texto escondido; tendremos un espacio en blanco. Lo mismo para un screenreader; es muy probable que ignore el contenido. Si vamos a usar el image-replacement, deberíamos de definir que es solo para el screen y no otro tipo de media, o definir diferentes reglas para los diferentes tipos de media. Abuso de la técnica Y vamos, que no solo nos vamos a imagenes de contenido. Otro ejemplo es el logo de una compañía. Un anchor con una imagen dentro y unos buenos atributos ala y title son más que suficientes (y semánticamente correctos) para el logo de una web; e incluso nos da la oportunidad de convertir el tag h1 en lo que verdaderamente es: el título de la página (y no el nombre de la empresa y/o de la web). De esta manera, el logo y el nombre de la empresa serían una imagen hasta arriba, y nuestra tag <h1> sería el título de la página que estamos viendo (por ejemplo: el título del post en un blog). Mi recomendación: ¡No todo es una lista! El punto es que no todo es una lista. Los menús son una lista de secciones a las que puedes acceder; lo mismo con un breadcrumb, por ejemplo; pero ¿una oración sería una lista de palabras? Digo, es un ejemplo algo drástico, pero es para demostrar el punto: abusamos de esta técnica. Al punto de que he visto (y también me declaro culpable de esto) una lista de DOS links: login-register. ¿Eso les parece una lista? Claro que no, porque no lo es. La idea de que “un menú es una lista” se ha desviado mucho de su realidad. Muchos desarrolladores meten listas al por mayor y, en algunos casos, limítan la cantidad de elementos que pueden entrar por cuestiones de dimensión. También se da el caso de tener problemas al cambiar una propiedad global a la tag <ul> y afecta a nuestras otras listas, teniendo que agregar un estilo que sea inversamente proporcional al que asignamos globalmente. Un ejemplo Supongamos que tenemos el siguiente HTML: Y su CSS: Como pueden ver, la tag <li> no tiene el atributo margin declarado. Ahora vamos a pensar que queremos darle estilo a todas nuestras listas de contenido, y por alguna razón, necesitamos agregar el atributo “margin-left: 50px“. Simplemente agregaríamos algo como esto a nuestro css: Si volvemos a nuestro menú verás que se ha roto. Para corregir el error, tendríamos que ir a nuestro CSS y especificar claramente que para esta lista el margen izquierdo es 0: Incluso tal vez tendríamos que usar el !important para hacer que funcione. Esto fue un ejemplo burdo, pero imagínense tener que arreglar 5 o 6 menus que tienen el mismo problema. Ahora imagínense tener que corregir no solo uno, sino varios atributos para cada menú. El resultado sería un CSS enorme y poco práctico, o un HTML lleno de clases o ids. Y si la especificidad (¿Cómo diablos se dice “specificity” en español?) de los elementos no fue la adecuada, los problemas crecen todavía más. Mi recomendación Mi nombre es h1 h1′ h1” Tenemos seis niveles de titulares. SEIS. Sin embargo, casi nunca llegamos a ver ni siquiera el 3 en la mayoría de las webs. Y no digo que TENGAMOS que usarlos; podemos tener una web con pocos contenidos; pero caemos en un problema enorme al momento de usar los titulares: repetimos los niveles. Los niveles desde mi punto de vista Aquí entramos en un poco de discusión: ¿El título de la página es el nombre del sitio (sitioweb) o el nombre del post que estoy viendo (Algunos errores del diseño web)? No vamos a entrar mucho en detalle, ni yo mismo estoy seguro de esto; pero una cosa si es segura: sea cual sea, solo existe Para este ejemplo, diré que el nombre del blog es el nombre de la página que estamos viendo. Por lo tanto, dentro de nuestra tag <h1> iría “sitioweb”. Este <h1> debería ser el ÚNICO de toda la página; pues no existe ningún elemento de mayor o igual jerarquía que él. Debajo de este pueden ir infinidad de <h2>, <h3>, <h4>, <h5> y <h6>’s que podemos agregar a diestra y siniestra; y aquí vamos a ver un nuevo problema: la mala jerarquización de nuestras páginas. Jerarquías en tu web El problema que quiero mencionarles es la mala colocación de los encabezados. Veamos el ejemplo anterior: El título de la web es <h1>sitioweb</h1>; el siguiente sería el título de la página que estamos viendo, es decir, <h2>Algunos errores del diseño web</h2>. Aquí es donde empiezan los conflictos, y es que la gente suele usar <h2> para los títulos de los menus (incluso otro <h1>), digamos; y no están al mismo nivel jerárquico. Hay que determinar bien qué elemento va en qué nivel de jerarquía. La solución Los hacks no son una solución, son un problema Una de cada dos veces, si no es que todas las veces, debemos corregir errores que Internet Explorer (u otro navegador) nos da al momento de mostrar nuestra web. Vamos, que con tantas opciones y tantos motores sería difícil que las diferencias no existieran. El problema es que, muchas veces, el navegador que nos muestra el error es el ÚNICO navegador que muestra ese error. Todos los demás funcionan perfectamente. Esto quiere decir que tenemos que, de alguna manera, modificar solamente ese navegador y nada más que ese navegador. Los hacks, ¿una solución? El problema viene cuando el navegador saca una actualización y corrige el error que te orilló a usar el hack de primer instancia. ¿Qué pasa? Pues todo se jode. La nueva regla que usaste mediante el hack también es leída por la nueva versión del navegador y al aplicar el hack, se jode todo. (de ahí que considere que la elección de microsoft de eliminar el star hack fue una excelente decisión). ¿La solución? Realmente no creo que haya una “solución” concreta para este caso, mas que el dejar los hacks como ÚLTIMO RECURSO, porque en verdad, a la larga, traerán más problemas que soluciones. ¡Hola! Me llamo “naranja” Nada difícil. Nuestro HTML: Y nuestro CSS: Vamos, en teoría es fácil. Pero aquí está el error: “naranja”. ¿Qué putas es “naranja”? Pues un color (o una rica fruta). Pero no nos da una idea del contexto. Ni puta idea del contexto, en realidad. Solo nos dice “naranja”. Ok, es naranja. ¿Qué es naranja? ¿El borde? ¿El color de fondo? ¿El color del texto? ¿El desayuno? Un mejor nombre de clase sería “promocion”. Así ya sabemos que esa división es una promoción, y no un “naranja” (que nos deja muy vagos). La solución ¿A none voy? Una de estas nuevas mejoras es la de enviar formularios automaticamente, sin necesidad de un boton de submit. Esto hace que las consultas ean mucho más rápidas y no se tenga que recargar toda la página. El error que viene aquí es el no usar javascript no obtrusivo. En terminos burdos, un javascript no obtrusivo (unobtrusive javascript) es aquel que NO es indispensable para la accesibilidad de la web. Vamos, que puedes enviar el formulario sin necesidad de tener javascript activado. El error en detalle Pero el problema no se limita a formularios. Algunas funciones que jalan con la tag <a> también sufren de este problema. Un ejemplo es la web emuxperts. Si desactivan javascript y visitan la web, no podrán navegarla; pues todos sus hipervínculos son generados por javascript. Otro ejemplo que encontré fue la pequeña clase para mootools, mootabs. Es un excelente script para generar tabs dinámicas usando javascript, pero tiene un enorme fallo: no utiliza enlaces para generar las tabs. De hecho, si intentas agregar un hipervínculo al <li> (que es lo que usa para generar las pestañas), se llega a romper. Claro que existen soluciones; pero el script en esencia no utiliza enlaces, lo cual te genera un código inaccesible para los usuarios y, peor aún, para los buscadores. La solución Este es un error que muchos desarrolladores están aprendiendo a omitir, y gracias a la tendencia del javascript inobtrusivo, está desapareciendo poco a poco; pero aún se repite mucho y es la razón de que esté en esta entrada. ¡No soy gordo! ¡Soy funcional! Lo bonito de todas estas librerías (y el origen de este problema) es la gran variedad de scripts que se han creado. Como ejemplo basta ver la cantidad impresionante de clones de lightbox que existen. Y como estos, tenemos miles de scripts que podemos usar. El problema Vamos, creamos nuestra web y queremos tener un lightbox hecho con mootools, los chorrocientosmil efectos de scriptaculous, un script independiente para ordenar tablas, uno para generar directorios en forma de árbol, uno para buscar mientras el usuario escribe y eliminar el botón de enviar… en fin, llenamos nuestra web con javascript y, en el peor de los casos, con más de una librería. ¿El resultado? Una web impresionante, visualmente hablando, con miles de funciones y elementos que pretenden aumentar la accesibilidad y dejar al usuario contento; pero que pesa cerca del medio mega en puro código. El simple hecho de meter una librería de javascript a tu web aumenta el peso de la misma en unos 50kbs, aprox. A eso hay que sumarle los scripts que le vamos añadiendo, cada uno oscilando entre los 3 y los 25kbs. Sumale el peso de tu XHTML, de tu CSS, las imagenes… pff. Terminas con una web demasiado pesada para lo que en realidad debería ser. ¿La solución? Las tablas no son de satanás, ¡úsalas! Pero los desarrolladores web han caído en la idea de que las tablas son malas, y deben evitarse a toda costa. Incluso he visto gente que ha intentado crear una tabla usando divs y CSS nada más. Eso ha sido el peor error de semántica que yo haya podido presenciar en mi vida. El problema de las tablas Ahora bien, no solo existe este problema. Tambien tenemos que, al momento de usar las tablas, no pueden aplicarle el estilo que desean. Vamos, que el simple hecho de aplicar un borde de 1px a las celdas es un poco menos obvio de lo que parece. Mas cuando queremos agregar estilos a las celdas, a los encabezados, etc. Terminamos usando cientos de clases diferentes para algo que nos tomaría solo una o dos clases. El problema es que no sabemos darle estilo a nuestras tablas. Es más, nos abemos ni siquiera todos los elementos que la tabla puede tener y que nos sirve para darle estilo a la misma. ¿La solución? Con esto termino este post. Algo largo, y me faltó profundizar un poco en algunas cosas, pero el tiempo a duras penas y me da para escribir esto. Espero poder escribir más seguido, ¡mi gente! Que tengo varias entradas guardadas por ahí. Entre ellas una revisión a varios post que he hecho antes, con mejores y apuntes que no conocía al momento. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|













| |||