
|
|
| Moderador del foro: ZorG |
| Foro uCoz Información General Para los principiantes Identificar clientes por su IP |
| Identificar clientes por su IP |
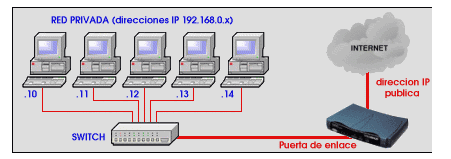
Identificar clientes por su IP: un mecanismo obsoleto Tomar la dirección IP de un cliente para tratar de individualizarlo es un método muy usado por la mayoría de los programas de Internet. Este método (que funcionó muy bien durante varios años), en el escenario actual de Internet ya no funciona, dando lugar a grandes confusiones. Este arículo describe detalladamente las razones de este cambio de escenario, y presenta las soluciones que pueden adoptar los programadores y webmasters para recobrar la exactitud perdida. Uno de los fundamentos técnicos de Internet consiste en que cada dispositivo u ordenador que se conecta a la red de redes debe poseer una única dirección IP (Internet Protocol) que lo identifique. Basados en esta afirmación, muchos programas en la web intentan identificar a sus visitantes usando la IP que éstos muestran en sus cabeceras de petición HTTP (lo que el explorador envía al servidor para indicarle: "quiero ver tal página"): • Muchos sistemas de encuestas (polls) no dejan votar más de una vez al día a una determinada IP, para evitar que un usuario pueda manipular los resultados votando muchas veces. Todos estos "controles" basados en la IP del cliente están asumiendo ingenuamente que cada PC conectada a Internet tiene una IP única que lo identifica, tal como decían los libros hace unos pocos años. Pero esto ya no es así, desde que Internet comenzó su expansión masiva y las direcciones IP comenzaron a escasear. Hoy nos encontramos con un escenario algo cambiado: es posible encontrar cientos, e incluso miles de PCs que comparten una misma IP. Pero el software que no se ha adaptado a estos cambios seguirá considerando que todo ese enorme conjunto de máquinas es un solo cliente, aunque en realidad se trate de todo un pueblo o una pequeña ciudad... • Entonces el mecanismo de encuestas dejará votar a una sola persona de esa ciudad (al primero que se levante a votar ese día). Los demás vecinos no podrán votar en el sistema de encuesta, que les dará el mensaje: "usted ya ha votado hoy". Cómo y por qué se comparten las IP El año pasado asesoré a otra empresa para conectar sus sistemas a Internet. Se contrató una línea de 2 Mbps, y el proveedor nos asignó 2 direcciones IP (una IP por cada 1 Mbps) 500 veces menos que hace 10 años! (en aquel entonces nos hubiesen asignado 1024 direcciones IP). Esto es porque los anchos de banda (las velocidades de transmisión de datos) han aumentado, pero el número de posibles direcciones IP sigue siendo exactamente el mismo desde que se inventó Internet. Los investigadores han diseñado un nuevo protocolo llamado IPv6 (IP versión 6, a diferencia del que está actualmente en uso que es IP versión 4). Pero el IPv6 aún está lejos de ser usado mundialmente, a pesar de que los sistemas operativos avanzados (como Linux) ya lo traen desde hace tiempo. Cuando el IPv6 esté en uso mundialmente, ya no existirán las situaciones problemáticas a que hago referencia en este artículo. Pero por el momento, los proveedores de acceso a la red están usando soluciones que posibilitan el acceso a mucha más gente al Intenet, pero por otro lado complican al webmaster y al administrador de servidores en la tarea de identificar a los clientes que acceden a los sitios web. NAT: la técnica más usada para compartir una IP El NAT no es la única técnica de acceso a Internet que invalida el viejo concepto de "1 cliente <--> 1 IP" que muchos programas pretenden usar como mecanismo de control. También exiten proxys anónimos, IPs dinámicas, etc. Pero a efectos de este artículo, trataremos el NAT como principal problema, sabiendo que las soluciones son las mismas para los diferentes escenarios técnicos. Posibles soluciones La "huella" de la PC: es el método más nuevo y el menos conocido y usado, pero también el más exacto. Consiste en obtener un sumario de las característcas de la máquina del ciente que establece una conexión. A su IP se suma el tamaño de su pantalla, la profundidad de color de su tarjeta de video, la versión del sistema opertaivo, el modelo y versión del explorador, si tiene instalado flash, quicktime, shockwave, Real Player, etc, etc. Leyendo la "huella" de los usuarios, aunque los veamos conectarse desde uan misma IP, sabremos por sus características que se trata de máquinas diferentes, y es posible identificarlas con gran precisión. Aún si todas las máquinas fueran iguales (dentro de una empresa, por ejemplo), pronto los usuarios les instalan plugins de software que modifican la huella de cada máquina. El sólo hecho de modificar el tamaño de pantalla modifica la huella también: de modo que en pocas horas, en un parque de máquinas exactamente iguales y que comparten una IP, se estaría en condiciones de individualizar la actividad que provenga de cada máquina. Conclusión Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Cómo saber la ubicación de un usuario Más de alguna vez nos hemos topado con la situación en la que necesitamos saber desde que parte del mundo nos está visitando un usuario, y en base a eso mostrar o no cierto contenido. Acá veremos que opciones hay para determinar la ubicación de un visitante. La forma tradicional: según la dirección IP Esta ip no representa el nodo real desde el cual nos visitan, pero usualmente es una buena aproximación del origen del usuario. Existen varias bases de datos dedicadas a recopilar este tipo de información, quizás la más popular sea la versión gratuita de IPligence (mientras no se use para fines comerciales y se les dé el crédito). Esta versión incluye 150,000 referencias por país, Microsiervos hizo un experimento en el que determinaron que es 95% exacta. Hay que tener en cuenta que IPligence te da su base de datos en formato CSV y con las IP’s convertidas a número enteros, pero ellos explican como hacer la conversión de IPs y como cargar estos datos hacia un gestor de base de datos. Deja que el mismo usuario te diga con HTML5 Si nos basamos en la especificación del W3C, para detectar la ubicación del usuario es bastante sencillo: La exactitud dependerá del agente con el cual se intente detectar la ubicación, los móviles que cuentan con GPS obviamente serán mucho más exactos que si se usan las redes WIFI cercanas para adivinar la ubicación. Tal vez convenga usar geo-location-javascript, un framework que agrupa varias propuestas de Geolocalización (aparte de la del W3C) en un solo lugar. Usarlo es igual de sencillo: Base de datos de IP’s vs HTML5 Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
|
Yo he leido esta monografia al respecto http://www.monografias.com/trabajos30/identificar-clientes-ip-mecanismo-obsoleto/identificar-clientes-ip-mecanismo-obsoleto.shtml
|
Habrá que probar a ver si funciona, aunque no sé que utilidad le veo identificar la ip de tus clientes.
|
Vosotros podéis ahora enterarse de los servicios que se ofrecen en una despedida de solteros porque este sector comercial está que retruena. Aquí en esta página os enteráis de los servicios disponibles en este tipo de eventos economiadehoy.es/noticia/39972/lifestyle/las-agencias-de-despedidas-de-soltero-un-negocio-en-auge.html con lo que podéis tener ideas de despedidas de soltero que podéis compartir con vuestros colegas o para planificar tu predespacho para tu boda. Esta que mola esta información y créanme que hasta me dieron ganas de casarme, yo que estoy tan solterito.
|
He leído tu artículo, soy perito informático y me ha interesado mucho. Ahora tengo un caso que debo localizar a una persona por su ip para realizar un informe pericial de sus comunicaciones por whatsapp y por email. Te felicito por el aporte y por el tiempo que le has dedicado a realizarlo.
Si algún día necesitas un https ://peritgirona.com perito judicial en Barcelona o Girona contacta conmigo y podemos colaborar. |
Cita jlmartir ( Tu enlace no funciona. Echa un vistazo al enlace que me gustaría ver. |
Gracias por compartir esta información, nosotros utilizamos STATCOUNTER para revisar estadísticas de visitantes, de que lugares nos visitan, horarios, navegadores y todo ese tipo de detalles, saber los términos que utilizaron y nos encontraron, etc etc.
Saludos. Conoce todo sobre Sistemas de Facturación Electrónica, Timbrado de Nómina y Contabilidad Electrónica http://www.facturacion-e.net
|
Esto es cierto, yo trabaje para una agencia consultora de mercadeo y para hacer sus encuestas estaban buscando la manera que sus resultados no se vieran sesgados por participantes que respondieran mas de una vez pues no lograban tener control sobre sus encuestadores. muy buen aporte.
|
voy a ponerlo en practica, gracias por la informacion

|



| |||
| |||