
|
|
| Moderador del foro: ZorG |
| Foro uCoz Ayuda a los webmasters Promoción del sitio Robots.txt – indexación del sitio web |
| Robots.txt – indexación del sitio web | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Con ayuda con el robot.txt estándar un sitio web se indexa más correcto. La web está compuesta de tal manera a que se vayan indexando sólo las páginas que contengan la información, y no todas las páginas seguidas (por ejemplo: página de entrada o de registro). Así que los sitios web de los usuarios de uCoz se indexan rápido y obtienen un nivel de prioridad más alto al comparar con los sitios donde se realiza la indexación de todo el contenido, con toda basura y las páginas innecesarias inclusive.
NOSOTROS RECOMENDAMOS INSISTENTEMENTE A QUE NO SE SUSTITUYA EL ARCHIVO ESTÁNDAR robots.txt POR UN SUYO . Pueden estar seguros de que de nuestra parte hacemos TODO LO POSIBLE a que las webs de nuestros usuarios se vayan desarrollando cuánto más rápido. ¡Ese es el lema de uCoz! Ese es el robots.txt estándar Quote User-agent: * Disallow: /a/ Disallow: /stat/ Disallow: /index/1 Disallow: /index/2 Disallow: /index/3 Disallow: /index/5 Disallow: /index/7 Disallow: /index/8 Disallow: /index/9 Disallow: /main/ Disallow: /admin/ Disallow: /secure/ Disallow: /informer/ Disallow: /mchat Para una web nueva existe una especie de cuarentena cuando es imposible todo tipo de regulación del archivo robots.txt. Con un alto índice de frecuentación, la cuarentena suele durar 2 semanas máximo. Los sitios poco visitados están en cuarentena 30 días. Al efectuar el pago de cualquier servicio adicional, cesa la cuarentena inmediatamente. El archivo robots.txt es de sistema y se ajusta a tu sitio web, no requiere una modificación alguna. Pero si lo quieres sustituir por un tuyo, hay crear en el bloc de notas o cualquier editor de texto un archivo de texto llamado robots.txt con un contenido requerido y cargar este archivo en la raíz de la web con ayuda del gestor de archivos o acceso de FTP. La dirección del archivo robots.txt es siguiente – http://dirección_de _tu_web /robots.txt El archivo robots.txt de la web en cuarentena se ve así:
Quote User-agent: UNetBot Disallow: /a/ Disallow: /stat/ Disallow: /index/1 Disallow: /index/2 Disallow: /index/3 Disallow: /index/5 Disallow: /index/7 Disallow: /index/8 Disallow: /index/9 Disallow: /panel/ Disallow: /admin/ Disallow: /secure/ Disallow: /informer/ Disallow: /mchat User-agent: * No se indexan los informadores pues exponen una información que existe YA en el sitio web. Por regla general ya está indexada esta información allá donde está inscrita.
Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Indexa tu sitio web en los buscadores antes de que lo publiques
Me he dado cuenta de que la mayoría de artículos sobre SEO (Search Engine Optimization) se enfocan en lo que debes hacer después de lanzar tu sitio web. Y la mayoría de las personas encargadas del lanzamiento del sitio se preocupan más por las palabras clave y las meta etiquetas. Pero casi nadie se percata que pueden tomar ventaja indexando su sitio antes de que sea lanzado. Con una pequeña preparación y unas horas de trabajo es muy fácil ser indexado por Google, Yahoo y MSN antes de tener el sitio funcionando. La clave para ser indexado es obtener links de sitio que ya han sido indexados. Cuando los buscadores rastrean esos sitios tu link será rastreado también y estarás dentro de su base de datos. Sigue estos cinco sencillos pasos un mes antes del lanzamiento de tu sitio y estarás un paso adelante: * Registra tu nombre de dominio. Quizá te sorprenda ver cómo muchas personas esperan hasta el último minuto para hacer esto. Registrar tu dominio antes, te asegura el que nadie ta lo gane además de que puedes sumar ventaja al lograr que se indexe. El ser indexado antes del lanzamiento de tu sitio web, te da una ventaja en tu SEO y el impacto de tu sitio será más rápido y casi inmediato. así que ¿para qué esperar? recuerda hacer esto un mes antes del lanzamiento.
(tomado de http://www.lawebera.es )
Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Guía Robots.txt Todos sabemos que la optimización de páginas web para buscadores es un difícil negocio, a veces posicionamos bien en un buscador para una frase clave en particular y asumimos que a todos los buscadores les gustarán nuestras página y por lo tanto estaremos bien posicionados para esa frase clave en cierto número de motores de búsqueda. Desafortunadamente esto sería un caso muy raro. La mayoría de los grandes buscadores difieren en algo, así que lo que te hizo estar bien posicionado en un buscador puede hacerte descender en otro. Es por esta razón que a alguna gente le gusta optimizar páginas para cada buscador en particular. Normalmente estas páginas serian ligeramente distintas pero esa pequeña diferencia podría marcar distancias cuando se intenta posicionar bien arriba, sin embargo, a causa de que los spiders de los buscadores indexan todas las páginas que encuentran, podrían venir a través de las páginas optimizadas específicamente para ese motor de búsqueda y notar que son muy similares. Por lo tanto, los spiders pueden pensar que estás haciendo spam y harán una de estas dos cosas, eliminarán tu web de su buscador o penalizarán tu web haciéndola bajar de posición. Que podemos hacer para decirle a Google que deje de indexar ciertas páginas que están pensadas para Altavista, bien, la solución es realmente simple y me sorprende que no se use más entre webmasters que optimizan para cada motor de búsqueda. Se hace usando un archivo robots.txt que reside en tu espacio web. Un archivo robots.txt es una parte vital de la batalla de cualquier webmaster contra ser baneado o penalizado por el buscador si él o ella diseña distintas página para distintos buscadores. El archivo robots.txt es simplemente un archivo de texto como sugiere su extensión. Se crea usando un simple editor de texto como Notepad o WordPad, procesadores de texto complicados como Microsoft Word no harían más que corromper el archivo. Este es el código que necesitar insertar al archivo: El texto rojo es obligatorio y nunca cambia mientras que el azul lo tienes que cambiar para adaptarlo al motor de búsqueda y a los archivos que quieras evitar. User-Agent: (Spider Name) el User-Agent es el nombre del spider del buscador y Disallow es el nombre del archivo que no quieres que indexe el spider. No estoy completamente seguro de si el código es sensible a las mayúsculas o no pero sé que ese código funciona, así que, para estar seguro, comprueba que la U y la A están en mayúsculas al igual que la D de Disallow. Tienes que empezar un nuevo lote de código para cada buscador, pero si quieres multiplicar la lista de archivos no permitidos puedes ponerlos uno debajo de otro. Por ejemplo - En el código de arriba he prohibido el acceso al spider de Inktomi a dos páginas optimizadas para Google (internet-marketing-gg.html & advertising-secrets-gg.html) y dos páginas optimizadas para Altavista (internet-marketing-al.html & advertising-secrets-al.html). Si Inktomi tuviera permiso para indexar estas páginas además de las páginas especificas para Inktomi, correría el riesgo de ser eliminado de sus búsquedas o penalizado por eso siempre es buena idea usar un archivo robots.txt Antes he mencionado que el archivo robots.txt reside en tu espacio web, pero donde de tu espacio web? El directorio raíz es donde hay que subirlo, si lo subes a un subdirectorio no funcionará. Si quieres bloquear ciertos buscadores de indexar ciertos archivos que no residen en tu directorio raiz simplemente tienes que apuntar al directorio correcto y listar el archivo como otro cualquiera, por ejemplo - User-Agent: Slurp (El spider de Inktomi) Si quisieras prohibir a todos los buscadores de indexar un archivo simplemente tienes que usar el carácter * donde estaría el nombre del buscador. Sin embargo, ten cuidado ya que el carácter * no funcionará en la linea Disallow. Aquí están los nombres de unos cuantos grandes buscadores, realiza una búsqueda con las palabras 'search engine user agen names' en Google para encontrar más. Excite - ArchitextSpider Asegúrate de comprobar el archivo antes de subirlo, ya que probablemente hayas cometido algún pequeño error lo que significaría que tus páginas podrian estar siendo indexadas por buscadores que no quieres que las indexen, o peor aún, que ninguna de tus páginas sea indexada. Ahora ya sabes como hacer un archivo robots.txt para dejar de ser penalizado por buscadores. Fácil, ¿verdad? ¡Hasta la próxima! Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Robots.txt : Todo lo que deberías saber El fichero robots.txt es un archivo de texto que dicta unas recomendaciones para que todos los crawlers y robots de buscadores cumplan (¡ojo! recomendaciones, no obligaciones). Pero comencemos por el principio. Un crawler es un robot de una entidad (generalmente buscadores) que acceden a las páginas web de un sitio para buscar información en ella, añadirla en los buscadores, etc. También son llamados spiders, arañas, bots o indexadores. Por ejemplo, Googlebot es el nombre del crawler del buscador Google. También existen otros como: • Impedir acceso a robots determinados: puede parecer contradictorio, pero algunos crawlers no nos proporcionarán sino problemas. Algunos robots no son de buscadores, e incluso algunos robots no son ni amigos. Pero de eso ya hablaremos más tarde. ¿Y entonces, que hay que hacer? Es muy sencillo. Sólo tenemos que crear un fichero de texto robots.txt y comenzar a escribir en el. Partiré del siguiente ejemplo donde permitimos la entrada a todos los crawlers (igual que sin ningún robots.txt): En User-agent debemos introducir el nombre del robot, y a continuación las rutas donde queremos prohibir que acceda. Algunos ejemplos: En algunos casos suele utilizarse en lugar de Disallow, la palabra Allow. Aunque por definición es correcta, es conveniente no utilizarla, puesto que las rutas omitidas se asumen que están permitidas por defecto, y algunos crawlers no entienden la palabra Allow. Es posible acumular varios Disallow bajo un mismo User-agent, pero no podemos utilizar varios User-agent encima de un Disallow. Bien, algún ejemplo: Este código impide al crawler del buscador de Live (MSN) acceder a la página links.html, y las carpetas private y photos (y todo su contenido) de nuestro sitio. Añadiendo el carácter # al principio de una linea podemos escribir comentarios que no interpretará el crawler. Es posible ir acumulando reglas para distintos crawlers, formando un robots.txt más largo y completo. Cada vez que escribamos un User-agent deberemos dejar una linea en blanco de separación. Además, existe una ligera adaptación que permiten usar comodines ($ y *) en las rutas en algunos crawlers (sólo Googlebot y Slurp): Se está indicando al robot de Yahoo, que no indexe los ficheros que terminen en .js (javascript), direcciones que empiecen por 2007 o 2006 (fechas), ni artículos con la palabra pagina (paginado de comentarios). Estos casos pertenecen a la idea de no indexar contenido duplicado. En la mayoría de los blogs, puedes acceder a un mismo artículo por las direcciones: Todo esto es contenido duplicado, una de las razones más importantes de penalización para un buscador, a no ser, claro, que te las ingenies para que sólo sea accesible desde una dirección. A la hora de ver los resultados te asombrarás lo bien que estarás quedando ante los ojos de Google, por ejemplo. Hay que tener mucho cuidado con usar cosas como Disallow: /pagina o Disallow: /*pagina, puesto que en lugar de bloquear lo que queríamos (carpeta pagina o artículos paginados), terminen bloqueando direcciones como /decorar-mi-pagina o /paginas-para-amigos/. Si revisas estadísticas y demás, también puedes observar que a veces algunos crawlers «se pasan» revisando nuestro sitio, y funden a peticiones a nuestro pobre servidor. Existe una manera de tranquilizar a los robots: Con esto le decimos al robot de noxtrum que espere 30 segundos entre cada acceso. Cuidado, porque Crawl-delay no lo soportan todos los crawlers (al menos MSNBot y Slurp si lo soportan, y Googlebot desde el panel de webmasters también). Finalmente, podemos también incluir un mapa del sitio en nuestro robots.txt de la siguiente forma: En RobotsTXT.org podrás encontrar documentación oficial si quieres profundizar y en esta búsqueda de Google encontrarás muchos robots.txt de ejemplo, incluso robots.txt optimizados para tu tipo de web. Además, también tienes un validador de robots.txt. Recordar a todos que con el fichero robots.txt no podemos bloquear los accesos por «fuerza bruta». Robots.txt es una recomendación del webmaster a los buscadores, que como son «robots buenos», las seguirán al pie de la letra. Existen otros «robots malos» (que buscan direcciones de correos o formularios para hacer SPAM) que no dudarán en acceder a los lugares que hayas prohibido si lo desean. Para bloquear estos, deberemos echar mano al fichero .htaccess, pero eso ya es otra historia... Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
6 razones típicas por las que tu sitio no es indexado Una de las primeras cosas que hacemos cuando un potencial cliente nos dice la famosa frase: “mi página no aparece en la primera página de los buscadores” es ver la cantidad de páginas indexadas que tiene su sitio. Y lo cierto es que poco sentido tiene que se preocupe de aparecer en la primera página de los buscadores si su portal ni siquiera está indexado. Normalmente, al hablar de motores de búsqueda nos referimos a Google, y el camino más sencillo y rápido de conocer que es lo que piensa el “gran Google” sobre tu página es realizar esta simple búsqueda en él: site: www.tusitio.com (donde www.tusitio.com será la dirección de tu página) Esta consulta te devolverá una lista con todas las páginas que Google ha indexado de tu sitio y de esta forma te resultará fácil calcular el porcentaje de indexación (que no es otra cosa que el número de páginas indexadas en relación al número de páginas totales de tu sitio). Y muy a menudo, cuando realizamos esta prueba comprobamos que Google no ha indexado todas las páginas que debería debido a algunos errores de optimización para motores de búsqueda. Y estas son algunas de las más comunes: 1- El archivo robots.txt Es un clásico error de optimización. Si has establecido el archivo robots.txt para inhabilitar completamente el paso a los motores de búsqueda luego no tue quejes de que sigan tus órdenes. Comprueba tu archivo robots.txt y asegúrate que está permitiendo el paso a las arañas de indexación. Sobre todo si encuentras que tu sitio no tiene ninguna página indexada, hazte un favor y asegúrate que en su interior no se encuentra el siguiente código: Si es así tienes un grabe problema ya que estás indicando a todos los buscadores que no deben indexar tu sitio. Te recomiendo que lo cambies por este código: 2- Tu servidor es demasiado lento Google no te penalizará directamente por que tu servidor responda demasiado lento, pero si lo hará indirectamente. Si al rastrear tu página nota que tu servidor se sobrecarga o responde demasiado lento a sus peticiones abandonará el rastreo para dedicar su tiempo a alguien más. Esto significa que no se rastreará al completo tu sitio antes que el robot de Google abandone tu sitio. Lo que a su vez, se transforma en menor número de páginas indexadas. Pero no podemos culpar a Google, no quiere ser responsable de bloquear tu sitio. A sí que en lugar de ello, antes que bloquear tu sitio prefiere buscar la información en las páginas de tus competidores. 3- Pueden pensar que eres una fuente de spam Si Google ha decidido que algunos comportamientos de tu sitio no son muy adecuados y están tratando de engañarlo o engañar a sus usuarios, probablemente tu página sea penalizada. Y si intentas aparentar lo que no eres, probablemente será consciente de lo que estás haciendo. A sí que si estas usando este tipo de prácticas para inmediatamente de hacerlo. Limpia tu sitio y envía una solicitud de readmisión a Google. Echarán un vistazo y si has hecho las cosas bien volverán a readmitir tu sitio e indexarte. También cabe la posibilidad que acabes de comprar el dominio y pagues las consecuencias de una penalización anterior a tu compra. En este caso te aconsejo que intentes descubrir qué es lo que era o parecía tu sitio antes de que tomases el control sobre él. Si estaba involucrado en alguna variedad de PPC poco amistoso con los buscadores puede que tengas graves problemas. 4-Mala Navegación ¿Tu navegación esta diseñada en Flash? ¿El 90% de tus enlaces están rotos o no redirigen correctamente? Bueno, entonces las arañas probablemente no van a ser capaces de acceder a las páginas, ni hablar ya de indexarlas. Si esta es tu situación tienes camino por recorrer…. 5-Poner innumerables trabas a las arañas Puedes poner trabas a las arañas de búsqueda de muchas formas distintas. Podría ser que tu código JavaScript esté ocupando las primeras 2000 líneas de código, que tu sitio requiera cookies o cualquier acción del usuario para poder entrar, que tus URLs sean dinámicas y poco amigables a los buscadores, que tu página de inicio redireccione 7 veces antes de mostrar realmente algo. Todas estas cosas cosas son barreras enormes para una araña hambrienta tratando de llegar a tu contenido. Elimina estas trabas y permite un acceso fácil a los motores de búsqueda. De otro modo ya puedes ir gastándote el dinero en publicidad si quieres que tu sitio tenga algo de visibilidad… 6-Sitio caído con demasiada frecuencia Si los buscadores intentan con frecuencia visitar tu sitio y este no está disponible, llegará un día en que dejen de intentarlo. No quieren indexar un sitio que no va a cargar cuando los usuarios intenten acceder a él. Asegúrate de que tu sitio Web no tiene problemas de alojamiento y alójalo en un servidor rápido. Si quieres hacer un diagnostico rápido, te recomiendo esta herramienta. Una sencilla y rápida herramienta que te devolverá una traza de las peticiones a tu sitio así como los tiempos de respuesta del servidor, enlaces rotos y posibles recursos no disponibles. Sencilla herramienta pero de gran utilidad. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
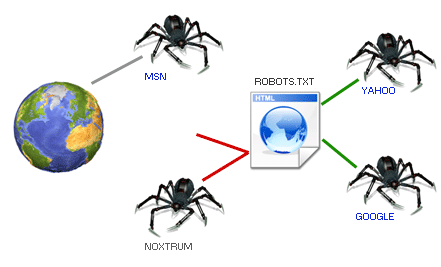
Características de los robots de búsqueda Indicando a los robots de búsqueda qué documentos de nuestra web deben indexar Los robots de búsqueda de WWW (también llamados wanderers o spiders) son los programas que buscan las páginas en el World Wide Web indexándolas para los buscadores. En 1993 y 1994 estos robots entraron en servidores de WWW e indexaron páginas que no debían: documentos personales, documentos confidenciales, duplicación de archivos, información temporal… Estos incidentes hicieron ver la necesidad de establecer los mecanismos necesarios para que los servidores de WWW pudiesen indicar a los robots de búsqueda las piezas a las que les estaba permitido acceder. El 30 de de junio de de 1994 (robots-request@nexor.co.uk) se llegó a un consenso estándar para trata esta necesidad, alcanzándose una solución operacional. Lo que sigue no es un estándar oficial promovido por una organización oficial. No es tampoco una obligación que se tenga que cumplir, por lo tanto no es seguro que todos los robots lo sigan. Se tiene que considerar como una facilidad a lo hora de proteger aquellos documentos y archivos que queremos que no indexen los motores de búsqueda. Para hacer la exclusión se crea un archivo en el servidor que especifica a los robots de búsqueda a qué archivos no tienen acceso y se le llama robots.txt. El robots.txt es un documento sencillo de texto plano, no se debe escribir en HTML, ni incluir expresiones diferentes al estándar ya que los robots no las reconocerán. Un simple documento de texto redactado con el Bloc de Notas de Windows es lo correcto. Debe estar alojado en la raíz del sitio, justo dónde alojamos la página index. http://www.dominio.com/robots.txt El formato del archivo está constituido por líneas que indican los valores para dos campos únicos: User-agent y Disallow. Los motores de búsqueda mirarán en la raíz del domino llamando a ese fichero especial "robots.txt" (http://www.dominio.com/robots.txt). El archivo le dice al robot de búsqueda qué archivos puede indexar, a este sistema se le denomina The Robots Exclusion Standard. En caso de que no exista el fichero robots.txt el robot considera que no hay ninguna exclusión y rastreará cualquier página del web site sin excepción. User-agent Se puede también utilizar el carácter comodín * para especificar que se excluyen todos los robots. Ejemplo: Podemos comprobar los nombres de los User-agent que han visitado el dominio para saber si hay peticiones de ese buscador. La mayoría de los motores de búsqueda importantes tienen nombres cortos para sus spider. Se incluirá una relación con sus características en la parte final de este post. Si es necesario determinar una política de acceso para varios robots de búsqueda se incluirán tantas líneas cuantos robots necesitemos especificar. Nunca se agruparán en una sola línea. Ejemplo: Es necesario que exista al menos un registro en el documento para que sea correcto. Disallow También se pueden especificar directorios. Ejemplo: Para bloquear el directorio cgi-bin de manera que todos sus documentos permanezcan sin indexar en el motor de búsqueda. Un archivo totalmente vacío para Disallow es exactamente igual cómo si no estuviera presente, por lo menos debe existir una línea de negación Disallow para que el directorio sea correcto. Una línea en blanco para Disallow indica que todos los archivos pueden ser indexados, se escribiría así: Si quisiéramos prohibir el acceso a todos los documentos “help” de nuestra web, tanto al http:www.dominio/cgi/help.htm como al http://www.dominio/help/index.html escribiríamos: En cambio, si quisiéramos prohibir el acceso a cualquier documento y fichero incluido en la carpeta “help” http://www.dominio/help pero permitir el acceso al documento “help.htm” del fichero "cgi" http://www.dominio/cgi/help.htm , escribiríamos: Espacio y comentarios en blanco Algún spider no lo interpretaría correctamente e intentaría ignorar el documento email.html # recopilación del formulario. Lo mejor es poner los comentarios en líneas independientes, por ejemplo: Un espacio en blanco al principio de una línea se permite pero no se recomienda por los mismos motivos, puede que sea mal interpretado por el spider. Ejemplos de archivo robots.txt Para prohibir que todos los spider indexen cualquier documento: Para evitar que todos los spider indexen nuestros directorios cgi-bin e images: Para prohibir al spider Roverdog, específicamente, que indexe cualquier archivo del sitio: Para prohibir a googlebot que indexe el archivo cheese.htm: Para indicar que ningún robot debe visitar cualquier URL que comience con "/cyberworld/map/" o "/tmp/", o "/foo.html": Para indicar que ningún robot debe visitar cualquier URL que comience con"/cyberworld/map/", a menos que el robot se llame "cybermapper": Documentos inaccesibles a todos los robots Enumerándolos: O incluyendo estos documentos en una carpeta llamada "norobots" y redactando el robots.txt así: Los documentos quedarán inaccesibles si tomamos la precaución de asegurarnos que nuestro servidor no está generando un listado del directorio norobots. Sin embargo, configurar un archivo de este tipo no es una garantía de que los documentos no puedan ser alcanzados por atacantes. Y hay que tener claro que el robots.txt es una medida de exclusión para los robots de búsqueda, no una medida de seguridad. Si los datos que contienen esos ficheros son sensibles: contraseñas de usuarios, datos personales etc… lo más serio es usar además un sistema de autentificación o SSL que asegure la completa privacidad de los documentos. Un ejemplo real de archivo robots.text es este: [http://www.google.com/robots.txt) Errores al redactar el robots.txt Otro error es hacer un rechazo múltiple en una línea poniendo en ella múltiples directorios como: Porque la mayoría de los spider malinterpretarán esa línea . Algunos intentarán buscar el directorio /css//cgi-bin//images/ o tendrán en cuenta sólo un directorio olvidándose del resto. La sintaxis correcta sería: Línea Enders en DOS: Se tiene que editar el robots.txt en el modo de UNIX y y hacer upload siempre en ASCII. Muchos clientes del ftp harán la transformación a la línea enders de Unix automáticamente (seamlessly), pero otros no. Un error que el estándar permite son los comentarios al final de la línea: Tiempo atrás han existido motores que buscaban la línea entera considerando # parte del nombre del directorio. Ahora no se tiene noticia de que alguno se equivoque o no pero ¿ merece la pena arriesgarse en un error semejante por ahorrarnos una línea de código? El estándar no trata específicamente los espacios de más en las líneas lo considera un mal estilo de escritura, pero tendríamos que preguntarnos una vez más si merece la pena arriesgarnos a ser malinterpretados por algo tan nímio. En ocasiones el spide interpreta la página de error 404 y las páginas de redireccionamiento como un documento HTML válido. Lo más aconsejable es indicar en el archivo .txt o en los metas tags que este documento no tiene que indexarse. El estándar determina que solo el User-agent y el Disallow pueden ir con máyusculas, lo que sigue es incorrecto: Otro error común es especificar cada archivo en un directorio como aquí: Se tiene que especificar con la opción del directorio de esta manera: La barra invertida indica al spider el límite del directorio. No hay que poner nunca Allow sólo Disallow, se rechazar para no permitir. Esto es incorrecto: Esto es correcto: ¿Qué hace un spider cuándo no hay barra invertida cómo aquí? Pues que dejará de indexar cualquier extensión de archivos con el nombre cgi y cualquier directorio nombrado cgi. Otro error es poner palabras clave en el directorio robots.txt o editarlo en formato HTML. Usar etiquetas meta para autorizar a los motores de búsqueda La etiqueta META se coloca en la sección HEAD del HTML. Un formato completamente simple sería (si queremos que no indexen los enlaces del index). Opciones de las meta tags Hay también dos órdenes globales que incluyen ambas acciones: all y none ALL=INDEX, follow y NONE=NOINDEX, nofollow Combinaciones posibles Visit-time Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
¿Qué es un WWW robot?
Usando nuestra terminología de "andar por casa" son robots que entran en todos los servidores de todo el mundo, buscan los documentos que están alojados en ellos, los incluyen en su index y luego nosotros podamos ir a ese index a buscar lo que necesitamos. ¿Qué diferencia hay entre un www robot y mi navegador? ¿Qué es un Agente? ¿Qué diferencia hay entre un www robot y un directorio? ¿Cuántas clases de ww robots hay? ¿Qué es un Search Engine? Ventajas de la existencia de estos robots de búsqueda 2.860 resultados en 0, 14 segundos de búsqueda, ¿cómo no amarlo?. Desventajas de los robots de búsqueda Los robots de búsqueda, con su afán de indexar, colapsaron ciertas redes en el pasado ya que cuando un www robot investiga un servidor adopta la apariencia de usuarios que visitan las web alojadas en él y cuanta más información exista en el servidor, más usuarios creará el robot para analizarla. Hoy en día existen mecanismos para que no se produzcan y la información suficiente para diseñar robots más eficientes. No hay que perder de vista que son máquinas, diseñadas con los conceptos más pluscuamperfectos del momento, pero máquinas que no son capaces de discernir entre un documento privado, un documento que sólo le interesa a mi grupo de trabajo, un borrador de una tarea pendiente, un documento temporal….. Lo indexan todo y este fue el motivo por el que se crearon los archivos "robots.txt", para indicar a los robots de búsqueda qué documentos tenían o no tenían que añadir a su base de datos. ¿Cómo decide un robot las webs qué va a visitar? La mayoría de los buscadores permiten también que se ingrese una dirección manualmente de manera que después la visite el robot para su indexación definitiva. Usan también otros recursos como listas de correo, grupos de discusión, etc. Todo esto les da un punto de partida para comenzar a seleccionar url’s para visitar, analizarlas y usarlas como recurso para incluirlas dentro de su base de datos. ¿Cómo indexa un documento el robot de búsqueda? ¿Cómo sé si un robot de búsqueda me ha visitado? ¿Por qué las solicitudes al archivo robots.txt orientan sobre las visitas realizadas por los robots de búsqueda a mi sitio? Un robot me ha visitado ¿qué tengo que hacer? ¿Cómo evito que un robot indexe mi sitio? La manera óptima de organizar un sitio es incluir en un directorio secundario todos los documentos y archivos que no queremos que indexen los buscadores, prohibir la entrada de los robots en ese directorio y configurar el servidor con unas buenas medidas de seguridad en el caso de tener documentación sensible. El robots.txt no es una medida de seguridad que garantiza la privacidad de los documentos, para eso existen otros métodos, el robots.txt es el resultado de un consenso para evitar que los robots añadan automáticamente a sus índices esos documentos. Mi proveedor no me da esa posibilidad ¿Existe otra manera para indicar a los robots qué zonas pueden indexar de mi sitio? ¿Por qué encuentro llamadas /robots.txt en mis ficheros? Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Domando a los robots de búsqueda: robots.txt Los robots de búsqueda, (también llamados crawlers, spiders o indexadores), sirven para leer una página web, recuperar su contenido y seguir los enlaces que el sitio tenga a otras páginas web. Existen tantos robots como buscadores. Con el tiempo se ha desarrollado un protocolo mediante el cual se pueden dar instrucciones a los robots creando así los ficheros “robots.txt”. Este fichero es el que se utiliza para indicar a los robots de rastreo lo que pueden y lo que no pueden hacer en tu sitio web. En este artículo veremos algunos útiles trucos para manejar a estos robots. Beneficios de un archivo robots.txt Algunas puntualizaciones Establecer el buscador de referencia: User-Agent Existen tantos robots como buscadores, esta es una lista de algunos de ellos, pero te dejo los spiders mas conocidos: • Google: Googlebot Bloquear o eliminar páginas: Disallow • Para bloquear un directorio y todo lo que contiene, inserta una barra inclinada después del nombre del mismo. • Para bloquear una página, insértala después de la línea Disallow. • Para eliminar una imagen de Google Imágenes, añade lo siguiente: • Para eliminar todas las imágenes de su sitio de Google Imágenes, añada lo siguiente: • Para bloquear archivos de un tipo determinado (por ejemplo, .gif), añada lo siguiente: • Para impedir el rastreo de todo nuestro sitio, permitiendo que se muestren anuncios de AdSense, inhabilite el acceso de todos los robots que no sean de Mediapartners-Google. Este robot no comparte páginas con el resto de user-agents de Google. Por ejemplo: • La directiva Disallow: / *? bloqueará cualquier URL que incluya el símbolo ?. Concordancia mediante patrones • Puede utilizar un asterisco ([]*[/b]) para que la concordancia se establezca con una secuencia de caracteres. Por ejemplo, para bloquear el acceso a todos los subdirectorios que comiencen por “privado”: • Para bloquear el acceso a todas las URL que incluyan un signo de interrogación (concretamente, cualquier URL que comience por el nombre de su dominio, seguido de cualquier cadena, signo de interrogación y cualquier cadena): • Para especificar la concordancia con el final de la URL, utilice $. Por ejemplo, para bloquear una URL que termine en .xls: Por último, si quieres profundizar, en RobotsTXT.org encontrarás la documentación oficial, ejemplos, e incluso un validador de robots.txt. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
UTILIZACIÓN CORRECTA DEL METATAG ROBOTS PARA LOS MOTORES DE BÚSQUEDA Google nos explicó bien cómo un bot de búsqueda acepta el metatag ROBOTS. Valores múltiples del content-parámetro Si una página contiene varios metatags de un mismo tipo, Google los unirá. Por ejemplo: serán comprendidos como Si los valores contradicen uno a otro, se tomará en consideración el más estricto. Así pues, si una página contiene los metatags el bot se subordinará al valor NOINDEX. Valores excesivos del content-parámetro Orientación del metatag ROBOTS directamente a Google-bot Pero si hay un deseo de crear diferentes instrucciones para diferentes motores de búsqueda, es mejor utilizar metatags especiales para cada motor de búsqueda, o sea, no crear un metatag ROBOTS junto con los específicos para un motor de búsqueda concreto. Google-bot comprende cualquier combinación sea en mayúscula o minúscula. Por eso cada de los metatags siguientes se interpreta de manera igual: Si tienes varios valores del content-parámetro, han de estar separados con coma. No importa si hay espacios o no. los metatags siguientes se interpretan de manera igual: Utilización del archivo robots.txt y metatags ROBOTS Más concreto: si un usuario bloquea las páginas con robots.txt, Google-bot nunca las escaneará y nunca leerá los metatags de estas páginas. Si en robots.txt no hay prohibición a indexar la página, perl ésta está bloqueada con ayuda del metatag, Google-bot abre la página, lee los metatags y en el futuro no la indexará. Valores válidos del content-parámetro del metatag ROBOTS: Unas cuantas palabras sobre el valor de “NONE” Pero hay web-masters que utilizan este tag para informar a los bots sobre la ausencia de cualesquiera limitaciones y así impremeditadamente bloquean el contenido de las páginas para todos los motores de búsqueda. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Robots.txt, nofollow y noindex Hasta ahora he comentado los trucos y mejoras en tu web para permitir que los buscadores la indexen pero, como es normal, hay zonas o secciones que no queremos que indexen, como el área privada de los usuarios o páginas con el mismo contenido pero menor relevancia. Pueden ser muchos los motivos por los que no quieras indexar una página o incluso una web entera, por ejemplo que está en BETA, es una página personal o no quieres problemas de contenido duplicado. Para ello, hay que decirle a los spiders (que son los robots que usan los buscadores para rastrear tu web e indexarla), que no lo hagan. Robots.txt Para crear el robots.txt basta con crearlo usando el notepad y el siguiente código: En User Agent se establece el buscador al que quieres hacer referencia, y bajo el, en cada disallow una url de tu web que no quieres que sea indexada. Si quieres establecer que todos los buscadores sigan esas instrucciones, basta con poner el signo * en User-Agent (aunque dado que cada buscador premia unas u otras cosas aveces puede interesar permitir que unos indexen lo que otros no quieres que vean). Para conocer los nombres de todos los buscadores busca aquí una lista, yo te dejo los spiders mas interesantes: • Google: Googlebot Cuidado al colocar varios spiders y un comodín, ya que los spiders no harán caso de lo que ponga el comodín si tienen su sección propia, de tal manera que lo siguiente permitiría a Google indexar tu web pero al resto de buscadores no: Lo mismo sucede si por error te olvidas de poner algo tras el disallow, estarías diciendo que permites que indexen toda la página: Respecto a las páginas que no quieres indexar, puedes colocar archivos, directorios enteros, tipos de archivos, parámetros, etc. Para ello puedes utilizar el asterisco como comodin (que representa uno o varios caracteres indefinidos) y el dólar ‘$’ que indica que la url debe finalizar ahí. Te muestro unos ejemplos: El anterior robots impediría el acceso al subdirectorio primavera, cualquier URL que contenga un QueryString (o el símbolo ?), los gifs y cualquier url en que se incluya el parámetro userid o subdirectorio en que se incluya el parámetro id. Si no utilizamos bien el $ podemos tener problemas, ya que sin él se especifica que cualquier URL que empiece por la cadena establecida no sea recorrida por los spiders, pero con él, se establece que deben terminar en eso. De forma que “/usabilidad/” impide el acceso al directorio usabilidad, “/*usabilidad” impide el acceso a cualquier URL que contenga usabilidad y “/*usabilidad$” impide el acceso a cualquier URL que termine en usabilidad. Ahora imaginemos que por error ponemos esto: Pretendiendo denegar el acceso a las páginas que contengan un QueryString vacío, estaríamos denegando en realidad cualquier página que contenga un QueryString, para lo primero debe ponerse el $ al final, indicando que tras el ? no debe haber nada mas y, si lo hay, entonces sí debe indexarse. Por último, si lo que buscas es cerrar la web entera a los buscadores, bastaría con poner la barra de la raíz así: Nofollow y Noindex Además del nofollow, también existe el noindex, que le dice a Google que, aunque si puede seguir ese enlace (y por tanto tener en cuenta la página a la que apunta) no debe indexarla en sus búsquedas, esta etiqueta también puede ponerse en un meta de la página para asegurarse, aunque si pones este meta, recuerda quitar la página del robots.txt, o Google no pasará por la página y no podrá verlo. Ten en cuenta que aunque le digas a Google en el robots que no rastree una de tus páginas, eso no implica que Google no la pueda indexar, ya que puede que haya un enlace a la misma en otras páginas, por lo que es necesario usar el meta noindex y quitar la página del robots para que vuelva a rastrearla y sepa que no la debe indexar. Las vírgenes tienen muchas navidades pero ninguna Nochebuena.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Hola un saludo a toda la comunidad de ucoz,mi pregunta es, porque me sale esto en los rastreadores
(Googlebot se encuentra bloqueado para http://celularestuning.ucoz.es/.) (Bloqueado por la línea 2: Disallow: / http://celularestuning.ucoz.es/ Gracias anticipadas a todos | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
si la has creado hace menos de un mes ucoz pone un bloqueo para las web que dura dos semanas o máximo un mes (se quita automaticamente)http://celularestuning.ucoz.es/robots.txt
Compartir es vivir :)
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Quote (emmanuelb11) (se quita automaticamente) Gracias por tu respuesta Post editado por piopio - Viernes, 2011-04-29, 8:52 PM
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
okas saludos cordiales amigo

Compartir es vivir :)
|




 estoy desendo que me quiten el bloqueo,la pagina lleva mas de 15 dias y tiene cerca de 200 temas,haber si la desbloquean antes del mes y consigo mas adiencia.Un saludo emmanuelb11
estoy desendo que me quiten el bloqueo,la pagina lleva mas de 15 dias y tiene cerca de 200 temas,haber si la desbloquean antes del mes y consigo mas adiencia.Un saludo emmanuelb11
| |||
| |||